ISE Cryptography — Lecture 07
Passwords, Keys, and Identity
This Lecture
- Six lectures built the cryptographic toolkit
- Symmetric: stream ciphers, block ciphers, MACs, hash functions, authenticated encryption
- Asymmetric: key exchange, public-key encryption, digital signatures
- Every primitive assumed a uniform random key
- We kept saying “generated uniformly at random” ad nauseam
- But what if we want to use something else as a key? What if we have a password, or a Diffie-Hellman shared secret, or the output of a KEM?
- We’re going to cover:
- Entropy: the hidden assumption behind every security proof, and why real-world secrets often violate it
- HKDF: conditioning structured high-entropy secrets into uniform keys; key hierarchies and envelope encryption
- Password hashing: raising the cost of guessing attacks against low-entropy secrets
- Identity protocols: how passwords are actually used in authentication, and why the conventional model is weaker than it looks
The Entropy Problem
Not-so-random numbers.
The Hidden Assumption
- Every symmetric and asymmetric primitive we have studied makes one assumption about keys
- The key is drawn uniformly at random from \(\{0,1\}^n\): every bit independent, every value equally likely
- This assumption is critical in every security proof
- Remove it, and the guarantees collapse
- We have never asked where such a key comes from in practice
- The answer is almost never “a uniform random bitstring”
- Real-world secrets have structure, bias, and entropy far below \(n\)
- Today’s lecture asks: what do we actually have, and how do we turn it into something usable?
Entropy
- Entropy measures uncertainty: how many bits would an adversary need to search exhaustively?
- A uniform \(n\)-bit key has \(n\) bits of entropy: \(2^n\) equally likely values, each with probability \(2^{-n}\)
- So a 128-bit key should have 128 bits of entropy
- A password chosen from a dictionary of 50,000 words has \(\log_2(50\,000) \approx 15.6\) bits
- A uniform \(n\)-bit key has \(n\) bits of entropy: \(2^n\) equally likely values, each with probability \(2^{-n}\)
- The relevant quantity for cryptography is min-entropy: the log-probability of the single most likely value
- \[H_\infty(X) = -\log_2(\max_x \Pr[X = x])\]
- If “password123” is the most commonly chosen password, selected by 10% of users, min-entropy is \(\log_2(10) \approx 3.3\) bits
- \(H_\infty = -\log_2(0.1) = -\log_2\!\left(\tfrac{1}{10}\right) = \log_2(10) \approx 3.3 \text{ bits}\)
- Average entropy can look healthy while min-entropy is low
- Common passwords skew the distribution badly!
- Entropy is a property of the distribution, not the value itself
- The adversary does not guess your specific password; they guess the most likely passwords first
The Entropy Ceiling
- No derivation function can produce more entropy than it receives
- The output is bounded by the entropy of the input, regardless of output length or computational cost
- This bound is the entropy ceiling: the maximum security any scheme built on that input can offer
- A SHA-256 hash of a single die roll has at most \(\log_2 6 \approx 2.6\) bits of entropy
- The output is 256 bits long, but only 6 values are possible
- Exhaustive search takes at most 6 tries
- A longer output does not necessarily mean more entropy!
- The output is 256 bits long, but only 6 values are possible
- A password run through HKDF produces 128-bit output, but only password-level security
- PBKDF2 and Argon2id raise the cost per guess, not the ceiling itself
- If the password has 40 bits of entropy, an attacker faces \(2^{40}\) guesses at elevated cost
- A far cry from \(2^{128}\) guesses against a uniform 128-bit key
- Hardening buys time, but it can’t supply entropy that was never there!
- If the password has 40 bits of entropy, an attacker faces \(2^{40}\) guesses at elevated cost
Three Tiers of Real-World Secrets
- Real-world secrets have very different entropy and distribution profiles
- Each tier needs a different cryptographic tool
- Mixing them up breaks assumptions and can lead to catastrophic failures!
- Tier 1: Uniform: hardware RNG or CSPRNG output
- \(n\) bits of output gives \(n\) bits of entropy, immediately usable as a cryptographic key
- Tier 2: High-entropy, structured: Diffie-Hellman shared secret, KEM output
- Hard to guess, but algebraically constrained: a group element, not a uniform bitstring
- Needs conditioning to become a usable key: HKDF
- Tier 3: Low-entropy: password, passphrase, PIN
- Human-memorable, so necessarily drawn from a small vocabulary
- Cannot be made cryptographically strong by derivation alone
- Needs hardening to make guessing expensive: password hashing
- HKDF is the tool for Tier 2. Password hashing is the tool for Tier 3.
- Applying HKDF to a password gives 128-bit output but only password-level security, a common (and serious!) mistake
Key Derivation
Conditioning high-entropy secrets into usable keys.
The Problem with Raw DH Output
- A Diffie-Hellman shared secret \(g^{\alpha\beta}\) is not a uniform bitstring
- It is a group element in \(\mathbb{G}\), a subgroup of \(\mathbb{Z}_p^*\)
- Group elements satisfy algebraic relations that the PRF assumption doesn’t account for
- Using \(g^{\alpha\beta}\) directly as an AES key violates the assumptions behind AES’s security proof
- The same applies to any KEM shared secret: high entropy, wrong distribution
- Hash functions are tempting but insufficient
- No theoretical basis that SHA-256 extracts uniform randomness from structured group elements
- We need a purpose-built key derivation function
HKDF: Not a General-Purpose KDF
- The HMAC-based Extract-and-Expand KDF (HKDF), defined in RFC 5869
- HKDF is specifically for Tier 2 secrets: high entropy, wrong distribution (not uniform)
- It removes algebraic structure from the input and produces keying material of arbitrary length
- It does not create entropy: a low-entropy input gives a low-entropy output
- A password fed through HKDF gives 128 bits of output but only password-level security
- Roughly 40 bits (a rough upper bound; empirical median is lower, and NIST SP 800-63B no longer publishes a specific figure)
- The adversary hashes guesses through HKDF and compares; they never invert it
- For passwords, use a password hashing function (next section)
HKDF: Extract-then-Expand
- HKDF takes: a secret \(s\), an optional salt, an optional info string, and a desired output length \(L\)
- Extract phase: HMAC absorbs the structured input and outputs a pseudorandom key \(t\)
- The salt improves extraction quality; a fixed public string is acceptable if no natural salt exists
- The salt is not secret: HMAC’s security as a randomness extractor does not require it
- Expand phase: \(t\) is used as a PRF key to produce \(L\) bytes of keying material
- The
infostring is a domain separator: different labels derive independent keys from the same \(t\) - One shared secret can produce separate keys for encryption, authentication, and export
- The
HKDF: The Algorithm
\[ \begin{aligned} &\textbf{Extract: } t \leftarrow \text{HMAC}(\mathit{salt},\, s) \\[4pt] &\textbf{Expand: } q \leftarrow \lceil L / \text{HashLen} \rceil \\ &\quad z_0 \leftarrow \varepsilon \\ &\quad \textbf{for } i = 1 \textbf{ to } q \textbf{ do:} \\ &\qquad z_i \leftarrow \text{HMAC}(t,\; z_{i-1} \,\|\, \text{info} \,\|\, \text{octet}(i)) \\ &\quad \textbf{return first } L \text{ octets of } z_1 \,\|\, \cdots \,\|\, z_q \end{aligned} \]
HKDF in Practice
- TLS 1.3 builds its entire key schedule on HKDF
- The ECDH shared secret is the input key material
- Different
infolabels derive independent keys: client traffic key, server traffic key, handshake key, resumption secret - The salt chains through the handshake; each stage’s output feeds the next extraction
- DHKEM in HPKE (RFC 9180) uses HKDF internally
- Ensures the KEM shared secret is uniform before it enters the key schedule
- Whenever a DH or KEM output needs to become a symmetric key, HKDF is doing the conditioning work
Key Hierarchies
- The expand phase can derive any number of independent keys from a single root secret
- Different
infolabels produce keys that are independent under HMAC’s PRF security - Compromising one derived key exposes nothing about the root or any sibling key
- Different
- This enables a key hierarchy: one master secret at the root, child keys derived for specific purposes
- TLS 1.3 is the worked example: one ECDH shared secret, fed through HKDF, yields client traffic key, server traffic key, handshake keys, and resumption secrets; all independent, all from the same root
- A password-derived key (from Argon2id or PBKDF2) can serve as the root of a hierarchy
- Example: from the password, derive one key for encryption and a separate one for signing
- Changing the password automatically invalidates every derived key
Envelope Encryption
- Envelope encryption separates key management from data encryption
- A data encryption key (DEK) encrypts the data directly using fast symmetric encryption
- A key encryption key (KEK) encrypts the DEK; the encrypted DEK (“envelope”) is stored alongside the ciphertext
- Why the separation?
- Rekeying: generate a new DEK and re-encrypt it under a new KEK; no need to re-encrypt all data
- Access control: a KEK grants access to the DEKs it protects; revoke by destroying the KEK
- HSM integration: the KEK never leaves the hardware; DEKs are derived on demand
- Used in AWS KMS, Google Cloud KMS, Azure Key Vault, macOS Keychain
- Password managers use this pattern: master password \(\to\) Argon2id \(\to\) KEK \(\to\) unlocks per-site DEKs
- The DEKs decrypt your stored credentials; the KEK is derived fresh on each login
Password Hashing
Slowing down the attacker, not the user.
The Entropy Gap
- A typical password has somewhere around 40 bits of entropy, a rough upper bound; empirical median is lower and NIST SP 800-63B no longer publishes a specific figure
- Common passwords cluster into a small vocabulary: dictionary words, names, dates, keyboard patterns
- A cryptographic key needs 128 bits or more of entropy
- This gap cannot be closed by derivation
- Running a password through HKDF gives 128-bit output but only password-level security
- The adversary hashes guesses and compares; they never invert the derivation
- The only lever available on the server side: make each guess expensive
- Cheap for the legitimate user: one evaluation at login
- Expensive for the attacker: many evaluations to search the password space
Plaintext Storage
- Store the password directly; compare on login
- Verdict: a database breach exposes every password immediately
- No computation required: the attacker reads the file
- Weak and strong passwords alike: entropy is irrelevant when the value is stored verbatim
- Real example: RockYou (2009), 32 million accounts stored in plaintext; the full list is still used as a cracking dictionary
Unsalted Hashing: \(H(\text{password})\)
- Store \(H(\text{password})\); compare \(H(\text{guess})\) against the stored value on login
- Rainbow tables: precomputed mappings from passwords to hashes for the entire vocabulary
- Computed once, applied to every database that uses the same hash function
- The attacker’s work is amortised across every future breach
- Weak passwords: fall in seconds via precomputed lookup; no computation needed per user
- Strong passwords: require per-user GPU computation, but the per-hash cost is nanoseconds
- Real example: LinkedIn (2012), 117 million accounts hashed with unsalted SHA-1; the majority cracked within days
Salted Hashing: \(H(\mathit{salt} \,\|\, \text{password})\)
- Generate a random salt per user; store \((\mathit{salt},\, H(\mathit{salt} \,\|\, \text{password}))\)
- Precomputation defeated: every user has a unique salt, making rainbow tables useless
- The attacker must recompute for every user; no amortisation across users or databases
- Weak passwords: still fall quickly; SHA-256 runs at billions of evaluations per second on a GPU, so dictionary passwords fall in minutes per user
- Strong passwords: the per-user computation time becomes prohibitive; \(2^{80}\) guesses at \(10^{10}\)/second takes over 3 million years
- Remaining problem: SHA-256 is designed to be fast; that property serves the attacker as much as the defender
Adding Pepper: \(H(\mathit{salt} \,\|\, \text{pepper} \,\|\, \text{password})\)
- A pepper is a secret value stored in the application layer, not the database
- Unlike the salt (stored in the database), the pepper lives in a config file, environment variable, or HSM
- An attacker who steals only the database cannot crack any hash without also recovering the pepper
- Weak passwords: safe against a database-only breach if the pepper remains secret
- Strong passwords: safe regardless
- Limitation: a full server compromise (database plus application layer) defeats pepper entirely
- Pepper hardens against database-only breaches; it is not a substitute for good hashing
- Orthogonal to salting and iteration count: can be layered on any scheme
Iterated Hashing: PBKDF2
- PBKDF2 (RFC 8018) replaced PBKDF1, whose output was capped at the hash length (16 bytes for MD2/MD5, 20 for SHA-1) and is now retained only for legacy compatibility
- PBKDF2 applies a PRF \(c\) times sequentially; each iteration depends on the previous and cannot be parallelised within a single guess
- OWASP recommendation: 600,000 iterations for PBKDF2-HMAC-SHA256
- This multiplies the per-guess cost by 600,000
- Future-proofing: increase \(c\) as hardware improves to maintain the same cost per guess
- Cryptographic agility!
- OWASP recommendation: 600,000 iterations for PBKDF2-HMAC-SHA256
- Weak passwords: still fall, more iterations slow the attacker but do not change how many guesses are needed to cover the dictionary
- Strong passwords: now practically infeasible to crack
- Remaining problem: PBKDF2 is compute-only; GPUs exploit massive parallelism across cores, and ASICs can be purpose-built to run PBKDF2 at scale
PBKDF2: The Algorithm
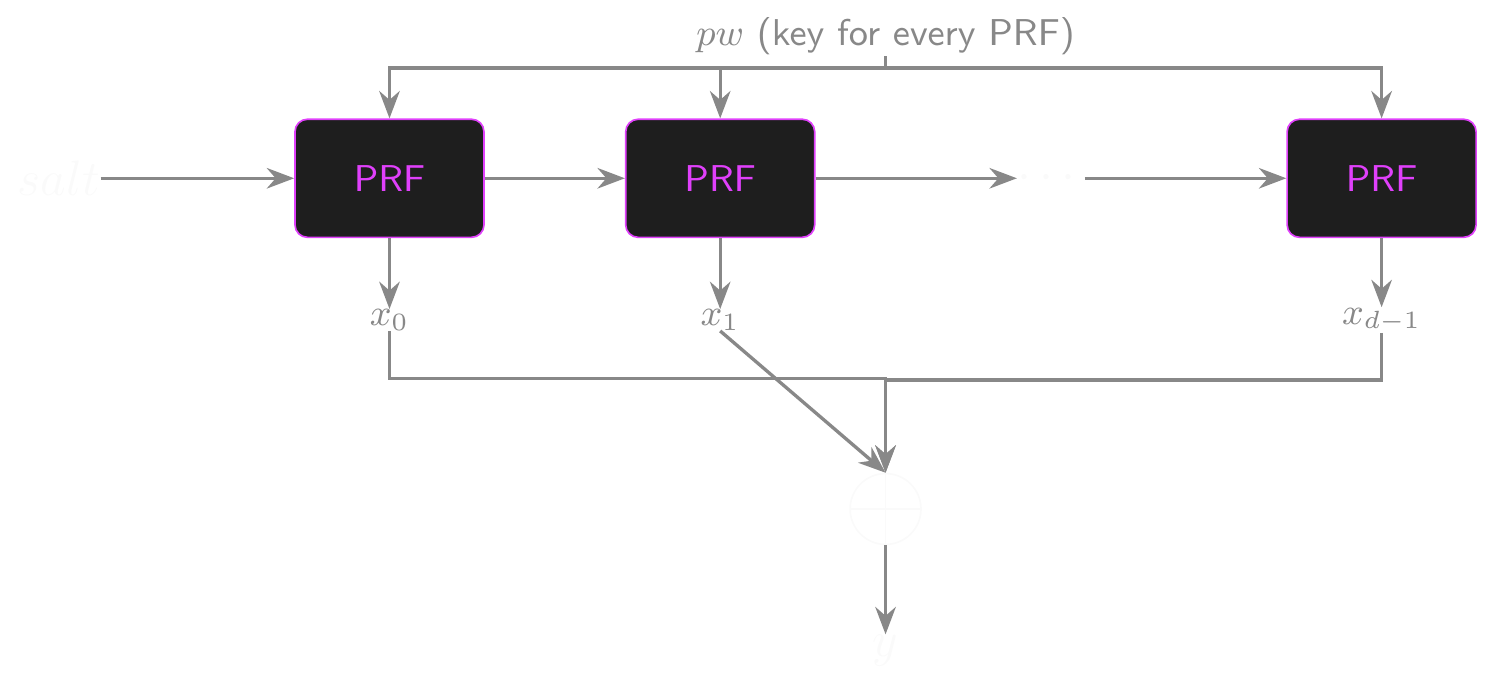
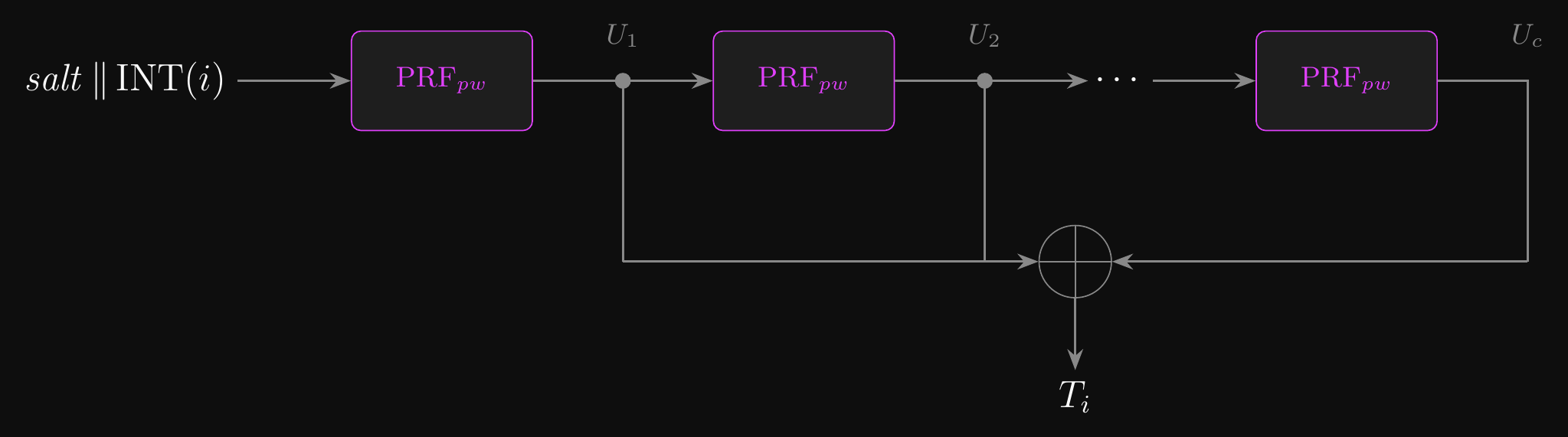
\[ \begin{aligned} &F(pw,\, salt,\, c,\, i): \\ &\quad U_1 \leftarrow \text{PRF}(pw,\, salt \,\|\, \text{INT}(i)) \\ &\quad \textbf{for } j = 2 \textbf{ to } c\textbf{:} \\ &\qquad U_j \leftarrow \text{PRF}(pw,\, U_{j-1}) \\ &\quad \textbf{return } U_1 \oplus U_2 \oplus \cdots \oplus U_c \\[6pt] &\text{PBKDF2}(pw,\, salt,\, c,\, L): \\ &\quad q \leftarrow \lceil L \,/\, \text{HashLen} \rceil \\ &\quad \textbf{return first } L \text{ bytes of } F(pw,\, salt,\, c,\, 1) \,\|\, \cdots \,\|\, F(pw,\, salt,\, c,\, q) \end{aligned} \]
- \(c\): iteration count — OWASP recommends 600,000 for HMAC-SHA256
- \(i\): block index; \(\text{INT}(i)\) is a 4-byte big-endian encoding, giving each block an independent PRF chain
- \(L\): desired output length; \(q = \lceil L / \text{HashLen} \rceil\) blocks are derived, concatenated, and truncated to \(L\) bytes
PBKDF2: One Block (\(F\))
Memory-Hard Hashing: Argon2id
- Memory-hard functions require large RAM allocations per evaluation, not just CPU time
- GPUs have limited per-core memory; ASICs face the same physical constraint
- Memory bandwidth becomes the bottleneck: raw compute advantage evaporates
- Argon2id won the Password Hashing Competition in 2015; it is the current recommended standard
- Three parameters: memory \(m\) (KiB), iterations \(t\), parallelism \(p\)
- Tunable: as hardware improves, increase \(m\) to keep attacker cost constant
- Weak passwords: still eventually crackable; entropy cannot be created by any hashing scheme
- The economics shift dramatically: RAM-seconds are expensive, not just CPU-cycles
- OWASP 2024 minimum: \(m = 19\,\text{MiB}\), \(t = 2\), \(p = 1\)
- Strong passwords: safe against GPU and ASIC attacks at current and projected hardware capability
Argon2: Three Variants
- The three variants differ in how the fill phase selects reference blocks
- Argon2d: data-dependent references
- Reference indices are derived from the content of the previously computed block
- Maximally memory-hard: every block depends on prior memory; no shortcut exists
- The access pattern encodes the password: an attacker sharing the same hardware can observe which cache lines are touched and recover password bits from the pattern
- Intended for settings where hardware side-channels are not a threat (e.g. proof-of-work)
- Argon2i: data-independent references
- Reference indices come from a deterministic counter; the access pattern is fixed regardless of the password
- Side-channel resistant: suitable for password hashing when shared-hardware timing attacks are a concern
- Slightly weaker memory-hardness: admits a time–memory trade-off via DAG-based optimisation; at least 3 passes are required to close it
Argon2: Three Variants (cont.)
- Argon2id: hybrid (recommended)
- First half of the first pass uses data-independent references; the rest uses data-dependent references
- Resists cache-timing attacks while preserving near-maximal memory-hardness overall
- RFC 9106 recommends Argon2id for general password hashing; it subsumes Argon2i in essentially all deployment scenarios
Argon2id: Setup
\[ \begin{aligned} &H_0 \leftarrow \text{BLAKE2b}(p \;\|\; \tau \;\|\; m \;\|\; t \;\|\; v \;\|\; y \;\|\; \text{len}(P) \;\|\; P \;\|\; \text{len}(S) \;\|\; S \;\|\; \cdots) \\[4pt] &B[i][0] \leftarrow H'(H_0 \;\|\; 0 \;\|\; i), \quad B[i][1] \leftarrow H'(H_0 \;\|\; 1 \;\|\; i) \end{aligned} \]
Picture memory as a \(p \times q\) grid: \(p\) lanes (rows), \(q = m / p\) columns, each cell a 1024-byte block; lanes can be filled concurrently
Bootstrap from a fingerprint of every input, then seed the first two columns of each lane
\(H_0\) commits to parameters \((p, \tau, m, t)\), version \(v\), and variant tag \(y \in \{0, 1, 2\}\) for Argon2d/i/id, followed by the length-prefixed password \(P\) and salt \(S\); all integer fields are 32-bit little-endian
Placing \(y\) before \(P\) is what domain-separates the three variants
\(H'\) is BLAKE2b extended to arbitrary output length; it stretches \(H_0\) into the \(2p\) seed blocks
After setup, \(2p\) blocks are filled
- The remaining \(p(q - 2)\) blocks are the work the attacker must repeat for every password guess
Argon2id: Filling Memory
\[ \begin{aligned} &\textbf{for } r = 0 \textbf{ to } t - 1 \textbf{ do:} \\ &\quad \textbf{for slice } s = 0 \textbf{ to } 3 \textbf{ do:} \\ &\qquad \textbf{for each lane } i \textbf{ and column } j \textbf{ in slice } s \;(j \geq 2) \textbf{ do:} \\ &\qquad\quad \textbf{if } r = 0 \textbf{ and } s < 2: \; (i', j') \leftarrow \phi_{\text{i}}(r, s, i, j) \\ &\qquad\quad \textbf{else:} \; (i', j') \leftarrow \phi_{\text{d}}(B[i][j-1]) \\ &\qquad\quad B[i][j] \leftarrow G(B[i][j-1],\; B[i'][j']) \oplus B[i][j] \quad (r > 0) \end{aligned} \]
Walk each lane left to right for \(t\) passes; every new block compresses its left neighbour with a reference block fetched from elsewhere in memory
Each pass is split into 4 slices of \(q/4\) columns; lanes are filled in parallel within a slice and synchronise at slice boundaries, so the reference set grows in lock-step
\(\phi_{\text{i}}\) picks \((i', j')\) from a counter (fixed access pattern), used for slices 0–1 of pass 0; defeats cache-timing side channels while the password is still recoverable from access traces
\(\phi_{\text{d}}\) picks \((i', j')\) from the content of \(B[i][j-1]\) (password-dependent pattern), used in every other slice; forces an attacker to actually keep the grid in RAM
\(G\) is a 1024-byte compression built from BLAKE2b internals
The trailing XOR on later passes binds each block to its prior-pass value at the same coordinates, so an attacker can’t reuse memory across passes or skip intermediate passes
Argon2id: Finalization
\[ \begin{aligned} &C \leftarrow \bigoplus_{i=0}^{p-1} B[i][q-1] \\[4pt] &\textbf{return } H'(C,\; \tau) \end{aligned} \]
- Once the grid is fully populated, collapse the last column into a single block and stretch it to the requested output length \(\tau\) (e.g. 32 bytes for a 256-bit key)
- XOR-ing the last column across all \(p\) lanes mixes every lane into the output: tampering with any block changes \(C\)
- \(H'\) stretches the 1024-byte \(C\) to the \(\tau\) bytes of derived key material that the caller asked for
What Server-Side Hardening Cannot Fix
- Every step in the cascade addressed an attacker who has stolen the stored hash
- None of it changes how many guesses are needed to reach a weak password
- Argon2id makes each guess expensive; it cannot make the search space larger
- Given enough time and resources, a weak password in a breach will be cracked
- Password policies and password managers matter alongside good hashing
- A long, unique, randomly generated password with Argon2id is extremely resistant to cracking
- A dictionary word with Argon2id is just expensive to crack, not infeasible
- Diceware passphrases and password managers attack the entropy problem directly: more entropy, not just a higher cost per guess
Choosing a Scheme
- Use Argon2id if available: current gold standard
- Use scrypt if Argon2id is not available
- Use bcrypt only if neither is available
- Use PBKDF2 if FIPS-140 compliance is required
- Always use parameters from NIST or OWASP
- Under-parameterised Argon2id offers no more protection than fast hashing at the same work factor
- All of the above assume the attacker is external: they steal the database and work offline
- There is a second class of attack we haven’t addressed…
- How do we sign in to a web app?
- Who knows your password? Just you?
Master Keys and Data Protection Keys
- NIST SP 800-132 names the password-derived key the master key (MK) and separates it from the data protection key (DPK)
- …the key that actually encrypts stored data (note that NIST doesn’t use the KEK/DEK terms)
- “The MK shall not be used for other purposes”
- Only to derive or protect DPKs
- Option 1: the MK is the DPK (directly, or a DPK derived from the MK via KDF)
- Simple: no separate key storage; the PBKDF output feeds straight into encryption
- Password change requires decrypting and re-encrypting every item protected by the retiring key
- The password’s entropy ceiling applies directly to data confidentiality
- Option 2: the MK acts as a KEK; a freshly generated random DPK protects the data
- Password change touches only the wrapped DPK; no ciphertext needs to be re-encrypted
- The DPK carries full random entropy independent of password quality
- One MK can wrap multiple DPKs for different data sets without re-deriving from the password
- Option 2 is the standard in practice: it is the envelope encryption pattern applied to password-derived keys
Identity Protocols
Better ways to use a password.
The Missing Threat
- The password hashing cascade assumed a passive attacker: they steal the database and work offline
- A different threat has been hiding in plain sight: the server itself
- In conventional password authentication, the server sees the plaintext password on every login
- The client sends the password (protected by TLS in transit); the server checks it against the stored hash
- The server has the plaintext in memory while doing that check
- A compromised or malicious server does not need to crack hashes: it logs what arrives
Password Reuse: The Credential Stuffing Problem
- Most users reuse passwords across multiple services
- A server that sees plaintext passwords on login can harvest them at the moment of authentication
- One compromised server yields working credentials for every service sharing that password
- No cracking required: the attacker uses the stolen password directly
- Credential stuffing: automated testing of harvested (username, password) pairs against every major service
- Billions of credential pairs from historical breaches are publicly available and actively used
- This is not a theoretical attack!
- Password hashing on the server does not address this at all!
- The hash protects the password in the database at rest
- The plaintext password is exposed at the moment of authentication
The Trust Model Problem
- Conventional password authentication requires unconditional trust in the server
- The server must be honest, uncompromised, and correctly implemented
- If the server is malicious or compromised, it has your password
- …and can try it anywhere else
- Phishing exploits the same structural weakness
- A fake login page is a server that claims to be someone it is not
- The client sends the password to whoever asks
- No way to verify the recipient’s identity at the application layer
- TLS authenticates the server’s certificate, but a phishing site can have a valid certificate for its own domain
- rootkits2go.biz having a valid certificate does not mean you can trust the software it’s offering
- The root problem: the server sees the password on every login
- So any server compromise is a credential compromise
What We Really Want
- A protocol where the server can verify knowledge of the password without ever receiving it
- Not just in transit: the server should never handle the plaintext, not even in memory at login
- Target properties:
- No live exposure: a compromised server during authentication cannot harvest the password
- No credential reuse: a stolen credential cannot be used against other services
- No offline cracking: what the server stores cannot be used to test guesses without client interaction
- Mutual authentication: both parties verify the other knows the shared secret
- Session key derivation: the protocol produces a fresh key for subsequent communication
- This is the password authenticated key exchange (PAKE) framework
Challenge-Response Authentication
- Server stores a verifier \(v = H(\text{password})\) at registration; at login, server sends a random nonce \(r\)
- Client computes \(H(v \,\|\, r) = H(H(\text{password}) \,\|\, r)\) and sends it as the response
- Improvement: the password is never transmitted in plaintext; the response is nonce-bound so it cannot be replayed
- The server verifies by computing \(H(v \,\|\, r)\) from its stored \(v\) and comparing
- An attacker who steals the verifier table can test candidate passwords offline by hashing them; no server interaction required
- Weak passwords: fall to offline dictionary attack against \(H(\text{password})\)
- Strong passwords: safer, but the offline cracking problem is unchanged
- Live exposure at login is addressed; offline cracking after breach is not
SRP: Secure Remote Password
- SRP (RFC 2945, SRP-6a in deployed systems) is a PAKE deployed in Apple HomeKit, iCloud Keychain, and several VPN implementations
- Registration: the client computes a verifier \(v = g^{H(\mathit{salt},\, \mathit{pw})} \bmod N\) and sends \((\mathit{salt},\, v)\) to the server
- Simplified: the standard includes the username in the hash
- The server stores \(v\); it never sees the password
- Authentication: a Diffie-Hellman exchange where both parties blend their ephemeral contributions with the password (client) and verifier (server)
- Both sides independently derive the same session key \(K\) from the shared DH value, the ephemeral exchanges, and their respective secret
- The server never handles the plaintext password during authentication
- Password reuse is addressed: a compromised server cannot harvest the credential and try it elsewhere
SRP: Protocol Exchange
\[ \begin{array}{lcl} \textbf{Client} & & \textbf{Server} \\[6pt] & \textit{Registration} & \\[3pt] v \leftarrow g^{H(\mathit{salt},\, \mathit{pw})} \bmod N & \xrightarrow{\quad(\mathit{salt},\; v)\quad} & \text{stores } (\mathit{salt},\; v) \\[10pt] & \textit{Authentication} & \\[3pt] A \leftarrow g^a \bmod N & \xrightarrow{\quad A \quad} & B \leftarrow kv + g^b \bmod N \\ K \leftarrow H(\ldots,\, \mathit{pw}) & \xleftarrow{\quad(\mathit{salt},\; B)\quad} & \\ & & K \leftarrow H(\ldots,\, v) \\[6pt] & \textit{both verify the other derived the same } K & \end{array} \]
SRP: Protocol Exchange (cont.)
- Weak passwords: vulnerable to offline dictionary attack against the verifier \(v = g^{H(\mathit{salt},\, \mathit{pw})} \bmod N\)
- An attacker with \(v\) can hash candidate passwords and check whether \(g^{H(\mathit{salt},\, \mathit{pw})} \equiv v\)
- Strong passwords: safe; an attacker must solve the discrete logarithm from \(v\)
- SRP’s structural weaknesses:
- Verifier table compromise enables precomputation attacks over the group for weak passwords
- Subtle algebraic vulnerabilities have emerged in deployed implementations
- TLS integration was proposed (RFC 8492) but never standardised
- SRP is widely deployed but the academic community considers it to have unfixed structural issues
OPAQUE: Oblivious Password Authentication
- OPAQUE (under IRTF CFRG standardisation,
draft-irtf-cfrg-opaque) is the modern replacement for SRP - The key idea: the client’s password is never processed by the server, even in blinded form
- Registration uses an oblivious PRF (OPRF): a two-party computation
- The server holds a secret key \(k\), and the client holds the password \(\mathit{pw}\)
- The client blinds \(\mathit{pw}\) with a random mask before sending
- The server evaluates the PRF on the blinded value
- The client unblinds the result to recover \(H(\mathit{pw})^k\);
- The server never sees the raw password at any point
- The client encrypts a keypair under this OPRF output and stores the ciphertext on the server
- Authentication: the OPRF runs again, the client recovers their keypair, and they complete a standard asymmetric protocol with the server
OPAQUE: Oblivious Password Authentication (cont.)
- What the server stores: an OPRF key and the client’s encrypted keypair
- Neither item allows offline password guessing without client interaction
- Weak passwords: resistant to offline cracking; the attacker must contact the server for each guess, enabling rate-limiting and lockout
- Online guessing attacks remain possible: access controls are still essential
- Strong passwords: safe against both online and offline attacks
- Deployed internally at Meta and several other large organisations; being evaluated for TLS integration
- The strongest guarantee in the cascade: even a fully compromised server cannot mount an offline dictionary attack
Trust Model Summary
| Scheme | Server sees plaintext? | Credential reuse? | Offline cracking after breach? |
|---|---|---|---|
| Plaintext storage | Yes, always | Yes | Immediately |
| Salted hash | Yes, at login | Yes | Yes (GPU) |
| PBKDF2 / Argon2 | Yes, at login | Yes | Yes (slower) |
| Challenge-response | No | No | Yes (verifier) |
| SRP | No | No | Weak passwords only |
| OPAQUE | No | No | No |
All PAKE schemes (challenge-response onward) provide mutual authentication and fresh session key derivation. The columns above capture breach and live-exposure properties only.
Where This Points
- For most systems: Argon2id + TLS is the right choice
- Good hash, transport encryption, acceptable trust model for typical deployments
- Simple to implement correctly; well-supported across all major languages
- For higher-assurance systems where server compromise is a credible threat: SRP or OPAQUE
- Stronger guarantees but significantly more complex to implement; library support is narrower
- WebAuthn and passkeys: a different direction; replace passwords with public-key credentials bound to a device
- The server stores a public key; the private key never leaves the user’s device
- Phishing-resistant by construction: the credential is bound to the origin, not transferable
- The likely long-term direction for consumer authentication
- For the EPIC project: choose a scheme and be able to defend the trust model it provides
Conclusion
Closing the gap between human memory and cryptographic uniformity.
What Did We Learn?
- Entropy is the hidden assumption behind every cryptographic security proof
- Three tiers: uniform (hardware RNG), high-entropy structured (DH/KEM), low-entropy (passwords)
- Each tier requires a different tool; confusing them breaks security
- HKDF conditions Tier 2 secrets into uniform keys via extract-then-expand
- Does not create entropy; removes algebraic structure, not fundamental uncertainty
- Powers TLS 1.3’s key schedule and DHKEM in HPKE; enables key hierarchies and envelope encryption
- Password hashing (PBKDF2, Argon2id) raises the per-guess cost for Tier 3 secrets
- Can protect strong passwords even after a breach; cannot rescue genuinely weak ones
- Argon2id’s memory-hardness defeats GPU and ASIC parallelism; pepper adds a server-side secret layer
- Identity protocols: conventional auth exposes passwords on every login; a compromised server harvests credentials directly, and password reuse multiplies the damage across services
- SRP: server stores a verifier, not the password; it is widely deployed but shows structural weaknesses
- OPAQUE: server never processes the password at any point; it is the current state of the art
Questions?
Ask now, catch me after class, or email eoin@eoin.ai