ISE Cryptography — Lecture 04
Message Integrity
Welcome back
- Midterm is done. Grades will be back on Brightspace soon.
- Today is the pivot point of the course
- Symmetric ciphers gave us confidentiality (L02, L03)
- Today we close the symmetric story with message integrity
- Next week we tackle the question those ciphers all dodged: how did the key get there?
- From here on, the EPIC project is the main act
- Every primitive we meet in L04 through L07 plugs into it
- Authenticated encryption for message bodies, signatures for identity, KEMs for key establishment
The Malleability Problem
Confidentiality is not enough!
Confidentiality vs Integrity
- We’ve built up strong defenses against eavesdropping adversaries
- Passive adversaries
- Can read transmitted messages, but can’t alter them or send their own
- But we’ve neglected active adversaries so far
- Malicious adversaries can modify messages in transit!
- If Bob receives a message from Alice…
- …can he convince himself that it wasn’t modified in transit?
- This is the question of message integrity
- Can any of the schemes we’ve looked at guarantee this?
- Integrity is orthogonal to message secrecy
- You don’t have to understand a message to alter it
- Many cases where integrity without secrecy is all that’s required
- Ethernet uses a CRC32, TCP uses a 16-bit checksum… any other examples?
CTR Mode is Malleable
- Consider a CTR-mode encrypted payment: Alice sends Bob a transfer
- The plaintext has a structured format with an amount, sender and recipient
- An adversary intercepts the ciphertext \(c = m \oplus F(k, \text{nonce})\)
- They don’t know the key. They can’t decrypt. But they don’t need to!
- CTR mode uses XOR: flipping a bit in \(c\) flips the corresponding bit in the decrypted \(m\)
- The adversary knows the structure of the message
- They XOR the appropriate ciphertext bytes to change the amount
- Bob decrypts successfully and sees a different amount
- The cipher did exactly what it was supposed to do
- It delivered confidentiality. Nobody read the message in transit
- But the adversary changed the message without detection
- CTR mode, CBC mode, and all CPA-secure ciphers that we’ve seen so far are vulnerable to this
- We asked the wrong question: we need integrity, not just secrecy
CTR Mode Bit-Flip Attack

Types of Integrity
- The adversary can intercept a message, alter it and forward it
- Checksum-style ideas can help with this
- But anyone can compute a valid checksum! We need to include a secret
- The adversary can also attempt a replay attack by resending old messages
- Messages can also be reordered
- Some messages may be dropped entirely
- Embedding some kind of sequence number in the message can help
- …but only if we ensure that the sequence number is valid!
- Keep this idea of tagging a message with associated data in mind for later
- Message metadata should be tamper-proof, but not necessarily secret
Authenticity
- Integrity asks if the message Bob receives has been altered in transit
- Some integrity checks guard against problems with the channel, e.g. Ethernet
- We’re interested in guarding against malicious third-party interference!
- Authenticity asks a related, but distinct, question
- Is the message actually from the supposed sender?
- Did it really come from Alice, or from an adversary?
- Can we use a shared secret to guarantee that the message is authentic?
- We’re going to tackle both these questions today!
Keyed and Keyless
- Keyless integrity checks are designed to detect transmission errors
- Random errors due to interference in the transmission medium
- Anyone can compute a valid CRC32 tag for an Ethernet message
- No secret involved, analogous to encoding rather than encryption
- We’ll discuss keyed integrity checks for our purposes
- An adversary shouldn’t be able to make valid tags for arbitrary messages
- Only those who know the secret key should be able to do so!
- More like encryption than encoding
- Tags are generally short, fixed-length bitstrings
- Only a small transmission overhead
MAC Definition
Tagging messages with a shared secret.
Message Authentication Code (MAC)
- A Message Authentication Code (MAC) ensures that a message has not been tampered with during transmission
- Uses a shared secret key between two parties to verify message integrity
- Why? So the adversary can’t produce valid MACs!
- A MAC system \(\mathcal{I} = (S, V)\) consists of two efficient algorithms:
- \(S\) is the signing algorithm used to generate tags
- \(V\) is the verification algorithm used to validate tags
- MACs are defined over the key, message and tag spaces \((\mathcal{K}, \mathcal{M}, \mathcal{T})\)
Signing, Verification, Correctness
- \(S\) is a probabilistic algorithm invoked as \(t \leftarrow S(k, m)\)
- \(t\) is the tag, \(k\) is the key, and \(m\) is the message
- \(S\) can be probabilistic, but doesn’t have to be
- \(V\) is a deterministic algorithm invoked as \(r \leftarrow V(k, m, t)\)
- The output \(r\) is either
acceptorreject
- The output \(r\) is either
- MACs must satisfy their correctness property for all keys \(k\) and messages \(m\)
- Pr[\(V(k, m, S(k, m))\) =
accept] = 1
- Pr[\(V(k, m, S(k, m))\) =
Randomised vs Deterministic
- Our definitions for computational ciphers also allowed for encryption to be probabilistic
- And we did! CBC with a random IV is probabilistic encryption
- With MACs, probabilistic versions are also common in practice
- Deterministic MAC system
- Same input \((k, m)\) always produces the same tag t
- Verification is simple:
acceptif \(S(k, m) = t\) - Guarantees unique tag per message
- Randomized MAC system
- Same \((k, m)\) might produce different valid tags on different runs
- May provide better trade-offs in terms of security and efficiency
- Both types can be secure!
The UF-CMA Game
Existential unforgeability under chosen message attack.
Defining MAC Security
- Let’s take a conservative approach to security. If a MAC can hold up in a hostile environment against powerful adversaries, then it’s good for day-to-day use too!
- As usual, let’s build an attack game to demonstrate!
- Let’s hold the key \(k\) constant, like we did for cipher attack games
- The adversary can request tags for millions of arbitrary messages of their choice
- They can request \(t = S(k, m)\) for arbitrary \(m\)
- The result is a signed pair \((m, t)\)
- This is called a chosen message attack
- We challenge the adversary to forge a new valid message-tag pair \((m, t)\)
- New? Has to be different from all of the signed pairs generated so far
- This is called an existential MAC forgery
Why Chosen Messages? Why Existential Forgery?
- Chosen message attack seems too generous to the adversary. Why allow it?
- In practice, adversaries often can trigger MACs on messages of their choice
- A web server might MAC cookie values an attacker controls
- A protocol might authenticate attacker-influenced metadata
- If the MAC is secure even when the adversary picks the messages, it’s secure everywhere
- Existential forgery seems too weak. Who cares about forging a random message?
- If the adversary can’t forge a tag for any message of their choosing…
- …they certainly can’t forge one for a specific target message!
- Conservative definitions make for stronger guarantees
MAC Security: Formal Definition
- The challenger picks a random \(k \in \mathcal{K}\)
- \(\mathcal{A}\) issues \(Q\) signing queries to the challenger
- The \(i\)th signing query is a message \(m_i \in \mathcal{M}\)
- The challenger computes \(t_i \leftarrow S(k, m_i)\) and returns \(t_i\) to \(\mathcal{A}\)
- \(\mathcal{A}\) stores the signed pair \((m_i, t_i)\)
- \(\mathcal{A}\) outputs a candidate forgery pair \((m, t) \in \mathcal{M} \times \mathcal{T}\)
- Where \((m, t)\) is different from all of the signed pairs queried by \(\mathcal{A}\)
Winning the MAC Game
- \(\mathcal{A}\) wins if \((m, t)\) is a valid pair under \(k\), i.e. if \(V(k, m, t)\) =
accept- \(\text{MAC}_\text{adv}[\mathcal{A}, \mathcal{I}] = \Pr[V(k, m, t) = \texttt{accept}]\)
- \(\mathcal{A}\) is a \(Q\)-query MAC adversary
- A MAC system \(\mathcal{I}\) is secure if for all efficient adversaries \(\mathcal{A}\)
- \(\text{MAC}_\text{adv}[\mathcal{A}, \mathcal{I}]\) is negligible
- Secure MAC systems are existentially unforgeable under chosen message attack
MAC Security: Attack Game
Deterministic vs Randomised Security
- A MAC system can be deterministic or randomized
- For deterministic MAC systems, security implications are simpler
- The adversary must produce a valid tag for a new message
- Similar to block cipher unpredictability
- For randomized MAC systems, this is a stronger security property
- May be many valid tags for a given message
- A new, valid tag for an already-queried message is still an existential forgery!
- In general, having a valid tag for a message gives no useful information…
- To generate a valid tag for a different message
- To generate a new, valid tag for the same message
Verification Queries
- We could also allow the adversary to perform verification queries in addition to signing queries. This seems like an even more powerful adversary…
- But it turns out that the two attack games are equivalent (with an error term)
- Intuition: the challenger can just reply
rejectto all verification queries. If that answer is ever wrong, the adversary already submitted a valid forgery!
Why Freshness? Replay is Trivial
- Note that the UF-CMA game requires the forgery \((m, t)\) to be fresh
- The adversary can’t just replay a pair they already received
- This isn’t because replay attacks don’t matter. They absolutely do!
- Replaying a valid “transfer funds” message is a real attack
- But replay protection is a protocol-level concern, not a MAC-level concern
- Sequence numbers, timestamps, and nonces handle replay at the protocol layer
- The MAC’s job is to prevent the adversary from creating new valid tags
- If they can’t forge, they can only replay (which the protocol blocks)
One-Time MACs
Information-theoretic security for a single message.
The Polynomial MAC
- Before building multi-message MACs from PRFs, let’s see that perfect one-time security is achievable
- No computational assumptions needed! Secure against unbounded adversaries
- But only for a single message
- This mirrors the OTP/stream cipher pattern from Lecture 01
- The OTP is perfectly secret for one message; PRG-based ciphers extend to many
- The one-time MAC is perfectly unforgeable for one message; PRF-based MACs extend to many
- The limitation motivates why we need computational assumptions for multi-message security
The Polynomial MAC: Construction
- Construction: work in \(\mathbb{Z}_p\) for a large prime \(p\)
- Key is a pair \((k_1, k_2) \xleftarrow{R} \mathbb{Z}_p^2\)
- For a message \(m = (a_1, \ldots, a_v)\) with each \(a_i \in \mathbb{Z}_p\):
- \(S((k_1, k_2), m) = a_1 k_1^v + a_2 k_1^{v-1} + \cdots + a_v k_1 + k_2 \mod p\)
- Evaluate the message as a polynomial at \(k_1\), then mask with \(k_2\)
- Example: if \(m = (a_1, a_2, a_3)\), the tag is \(a_1 k_1^3 + a_2 k_1^2 + a_3 k_1 + k_2\)
- The message defines the polynomial; the secret \(k_1\) is where we evaluate it
One-Time MAC Security
- With a single signing query, the adversary learns one point on the polynomial
- The polynomial has degree \(v\), so one point reveals almost nothing about \(k_1\)
- And \(k_2\) acts as a one-time pad on the output
- For any message \(m' \neq m\), the probability of guessing the correct tag is at most \((v+1)/p\)
- With \(p \approx 2^{128}\), this is vanishingly small (\(\approx 2^{-128}\))
- But with two signing queries, the adversary learns two points
- Two points on a degree-\(v\) polynomial with a linear mask: \(k_1\) can be recovered
- \(k_2\) is then trivially computed
- The MAC is completely broken after reuse!
- This is the fundamental limitation: one-time security requires fresh keys
- For multi-message security, we need computational assumptions (PRFs)
- But one-time MACs are not just a curiosity: Poly1305 (used in ChaCha20-Poly1305) is exactly this kind of polynomial MAC
Building MACs from PRFs
The PRF-to-MAC reduction.
When You Have a Hammer…
- Let’s say we already have a secure PRF. Can we turn it into a MAC?
- Quick recall from L03: a PRF \(F : \mathcal{K} \times \mathcal{X} \to \mathcal{Y}\) is a keyed function that is indistinguishable from a truly random function, even to an adversary with oracle access
- Block ciphers like AES (under appropriate conditions) are secure PRFs
- No point inventing something brand-new, right?
- It’s surprisingly easy! Here’s how we can do it:
- Define \(S(k, m) = F(k, m)\), i.e. just apply the PRF to the message.
- To verify, check if \(F(k, m) = t\). If so, accept; if not, reject.
Tag Size and Message Size
- This gives us a deterministic MAC
- A single valid tag \(t\) exists for a given message \(m\) under a fixed key \(k\)
- The security comes from the PRF’s unpredictability
- If \(F\) is a secure PRF, attackers can’t predict tags for new messages
- Well, that was suspiciously easy, wasn’t it?
- How big is the tag if we use AES? 128 bits, so forgery probability is \(1/2^{128}\). That’s fine!
- How big is the message if we use AES? Also 128 bits. That’s a problem!
The Reduction: Intuition
- Let’s backtrack to our definition of MAC security. Does a secure PRF pass the test?
- To make this easier, let’s pretend that our PRF \(F\) is a truly random function
- The adversary can make as many queries as they want to, but it won’t help
- When they want to find \(F(m)\) for a new \(m\) they haven’t queried yet…
- They’re completely in the dark!
- \(F(m)\) is random and independent of previous signed pairs
- Their best strategy is to guess randomly, so the output space must be big enough
- Chance of guessing correctly is \(1/|\mathcal{Y}|\)
- \(|\mathcal{Y}|\) should be super-poly to make \(1/|\mathcal{Y}|\) negligible
From Random Function to Real PRF
- All very nice, but how does this help with a secure PRF?
- Secure PRFs are indistinguishable from truly random functions…
- And guessing or brute-forcing random outputs isn’t feasible…
- The same reduction pattern from Lecture 02 applies
- We’ll build an adversary \(\mathcal{B}\) that turns any MAC forger into a PRF distinguisher
- If the PRF is secure, the MAC forger can’t exist
The Reduction: Formal Argument
- Suppose adversary \(\mathcal{A}\) can forge a MAC with non-negligible advantage
- Build a PRF distinguisher \(\mathcal{B}\) that uses \(\mathcal{A}\) as a subroutine
- \(\mathcal{B}\) receives oracle access to either \(F(k, \cdot)\) or a random function \(f\)
- \(\mathcal{B}\) forwards \(\mathcal{A}\)’s signing queries to its own oracle
- When \(\mathcal{A}\) outputs a forgery \((m, t)\), \(\mathcal{B}\) checks if \(t\) equals the oracle’s output on \(m\)
- If the oracle is random, \(\mathcal{A}\) succeeds with probability at most \(1/|\mathcal{Y}|\)
- If the oracle is \(F(k, \cdot)\) and \(\mathcal{A}\) forges, \(\mathcal{B}\) distinguishes with the same advantage
- So \(\text{MAC}_\text{adv}[\mathcal{A}, \mathcal{I}] \leq \text{PRF}_\text{adv}[\mathcal{B}, F] + 1/|\mathcal{Y}|\)
- Secure PRF implies secure MAC
- Another proof by reduction, in the same shape as the PRG-based cipher reduction from L02
- We proved MAC security without knowing anything about how \(F\) works internally
- Only that \(F\) is a secure PRF
- The same reduction template recurs for digital signatures, CCA security, and key exchange
Long Messages
- As we’ve pointed out, there’s a minor problem with building MACs directly from secure PRFs like AES
- Messages tend to be a lot longer than the block size
- A MAC that can only verify integrity for 128-bit strings is pretty useless
- But wait! We’ve solved this problem for block ciphers already, haven’t we?
- Given a secure PRF on short inputs, let’s try to build a secure PRF on long inputs
- This is an analogous idea to block cipher modes of operation
- In fact, some modes of operation come with built-in authentication and integrity checks!
CBC-MAC and the Length Extension Problem
When prefix-freedom matters.
CBC-MAC
- Let’s start by setting some conditions for the secure PRF we’ll use as a building block
- \(F\) is a secure PRF that maps n-bit inputs to n-bit outputs
- \(F\) is defined over \((\mathcal{K}, \mathcal{X}, \mathcal{X})\) where \(\mathcal{X} = \{0, 1\}^n\)
- Our new PRF \(F_\text{CBC}\) maps messages in \(\mathcal{X}^{\leq\ell}\) to tags in \(\mathcal{X}\)
- \(\ell\) is poly-bounded
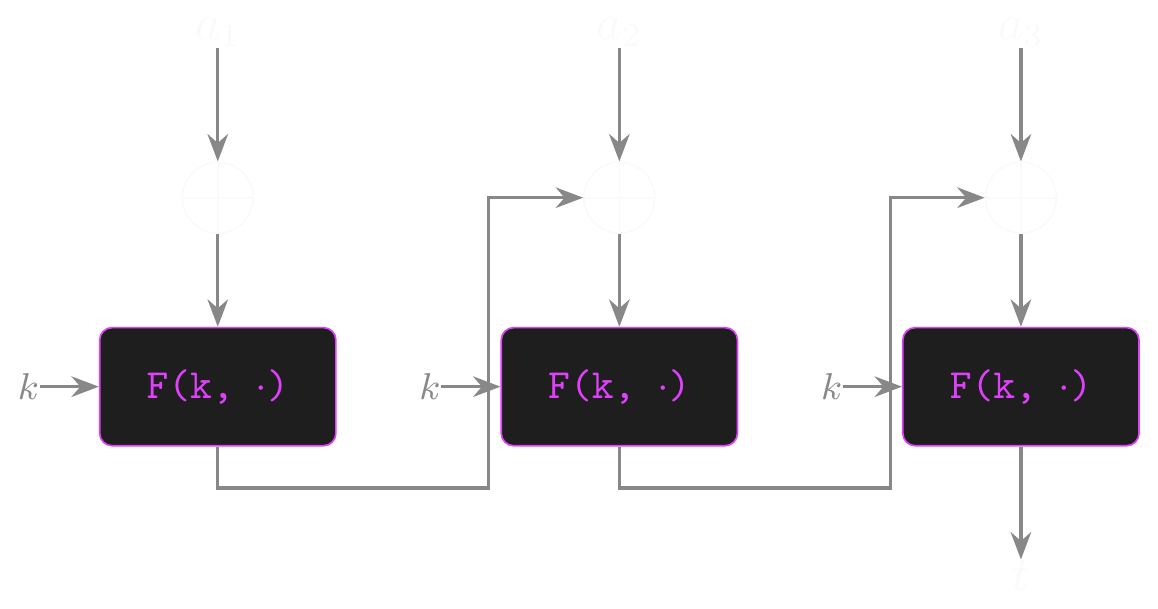
CBC-MAC: The Construction
- CBC-MAC is based on CBC mode: chain message blocks through a PRF to get one final output to use as the tag. Changing any message block changes the tag!
- Split the message into blocks as usual, so \(m = (a_1, a_2, \ldots, a_v)\)
- CBC-MAC uses a fixed, all-zero IV, so start with \(t = 0^n\)
- For each block, let \(t \leftarrow F(k, a_i \oplus t)\), and the final value of \(t\) is the tag!
- Just like CBC encryption, but…
- The IV is fixed, not unpredictable
- No intermediate outputs, just the final tag
Prefix-Free Security
- If adversaries are restricted to prefix-free queries, CBC-MAC behaves like a random function
- Prefix-free: no query \(m_i\) is a prefix of any other query \(m_j\)
- Example: \(\{(a_1), (a_1, a_2)\}\) is NOT prefix-free because the first message is a prefix of the second
- That makes CBC-MAC a prefix-free secure PRF
CBC Construction: \(F_\text{CBC}(k, m)\)
The Length Extension Attack on CBC-MAC
- CBC-MAC on its own is not a secure MAC for variable-length messages
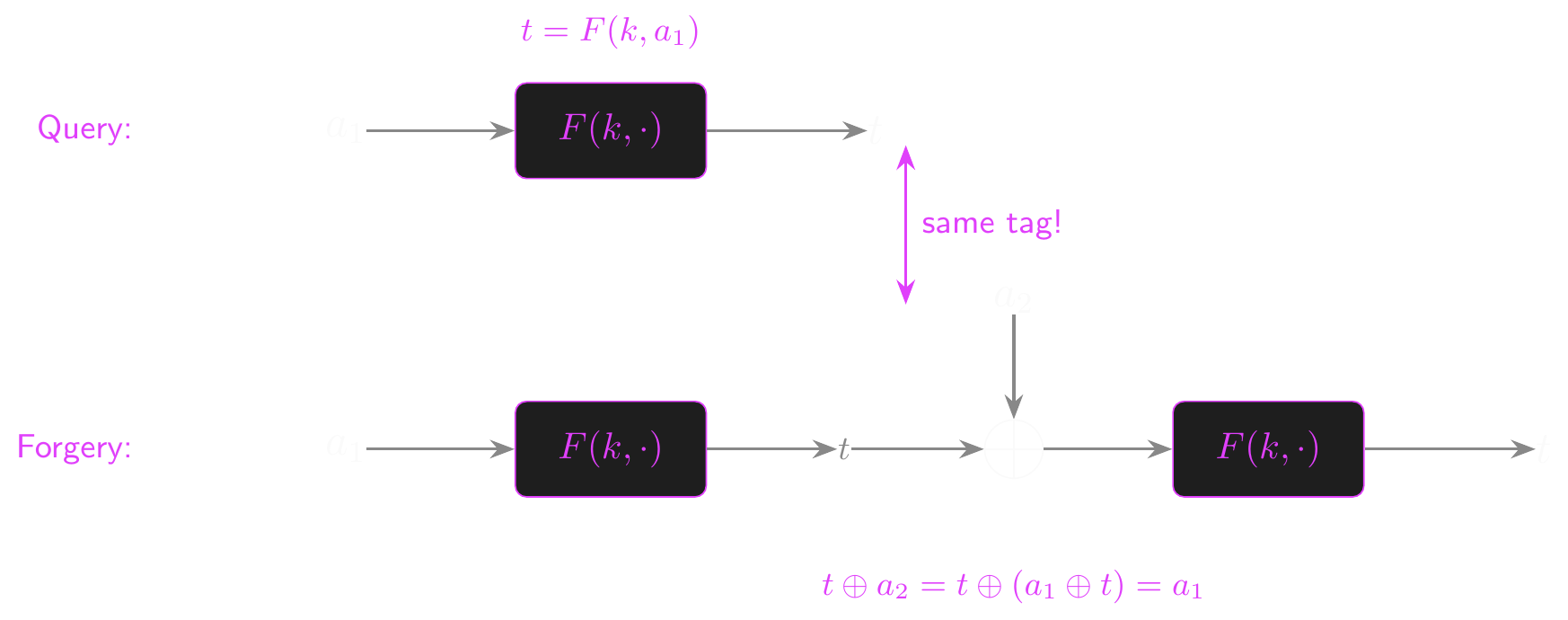
- The attack in four steps:
- Pick an arbitrary \(a_1 \in \mathcal{X}\)
- Request the tag \(t\) for the one-block message \(m = (a_1)\)
- Let \(a_2 = a_1 \oplus t\)
- Return \(t\) as a forgery for the two-block message \((a_1, a_2)\)
- The diagram on the next slide shows why this works. Each block flows through \(F(k, \cdot)\) with the previous chain output XORed in, so we can hand-craft the second block to re-enter the chain at \(a_1\).
Extension Attack on CBC-MAC
Why the Forgery Verifies
- Work through the algebra with \(a_2 = a_1 \oplus t\) and \(t = F(k, a_1)\)
- \(F_\text{CBC}(k, (a_1, a_2)) = F(k, F(k, a_1) \oplus a_2)\)
- \(= F(k, t \oplus (a_1 \oplus t))\)
- \(= F(k, a_1)\)
- \(= t\)
- So \(((a_1, a_2), t)\) is an existential forgery, and \(F_\text{CBC}\) is insecure as a MAC
- Root cause: the extension property of CBC-MAC lets an adversary continue the chain
- CBC-MAC is only secure when all messages have the same fixed length
Fixing CBC-MAC: Encrypted PRF and Prefix-Free Encoding
- Given a prefix-free secure PRF like CBC-MAC, how do we make it fully secure?
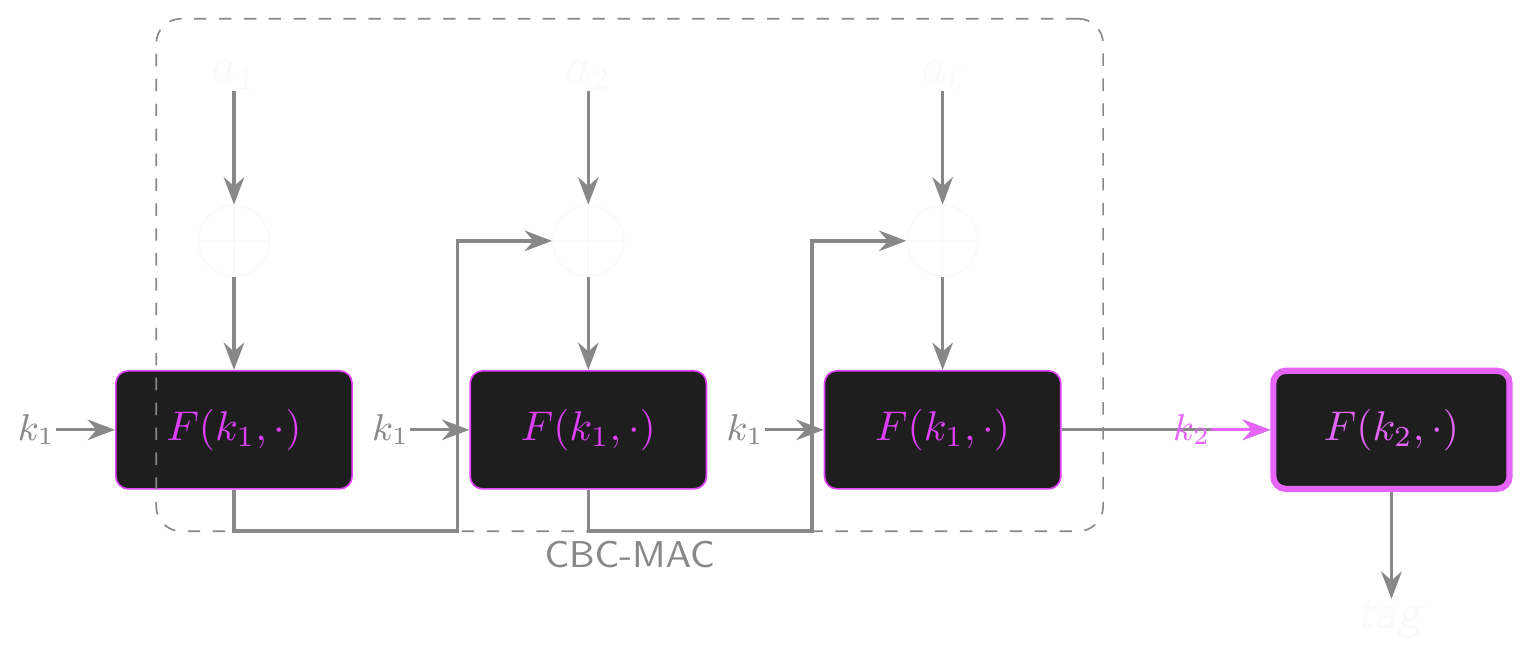
- Approach 1: Encrypted CBC-MAC (ECBC)
- Encrypt the final output with a second key: \(\text{ECBC}((k_1, k_2), m) = F(k_2, F_\text{CBC}(k_1, m))\)
- Hides the internal state; the extension property is broken
- Two independent keys are essential!
- Approach 2: Prepend message length
- \(pf(m) = (\langle v \rangle, a_1, \ldots, a_v)\) where \(\langle v \rangle\) is a fixed-width encoding of the block count \(v\)
- No message can be a prefix of another if lengths differ
- Drawback: message length must be known before processing starts (no streaming)
- Both work, but ECBC costs an extra PRF call per message and length-prepending kills streaming
- We want a construction that is streaming, efficient, and secure on variable-length input
ECBC Construction: \(\text{ECBC}((k_1, k_2), m)\)
CMAC: The Practical Standard
- CMAC fixes CBC-MAC without the drawbacks of ECBC or length-prepending
- Standardised by NIST in 2005; deployed as AES-CMAC in TLS, IPsec and IEEE 802.1X
- Streaming, one PRF call per block, no dummy blocks
- Only one key to distribute: the two subkeys below are derived from it, not shared
- Derive two subkeys \(K_1, K_2\) from the main key
- Compute \(L \leftarrow F(k, 0^n)\)
- \(K_1 \leftarrow 2 \cdot L\) and \(K_2 \leftarrow 4 \cdot L\) in \(\text{GF}(2^n)\) (cheap doublings)
- \(K_1\) is used when the final block is exactly \(n\) bits
- \(K_2\) is used when the final block is shorter and needs padding with \(10\cdots0\)
CMAC Signing and Why It Works
- Signing: run CBC-MAC as usual, but XOR the appropriate subkey into the last block before the final PRF evaluation
- Separate subkeys for full and partial last blocks prevent padding collisions
- Why does this work?
- The subkey XOR breaks the extension property: the final PRF input is no longer something an adversary can reproduce by appending blocks
- And the adversary does not know the subkeys, because computing them requires the main key
CMAC Construction
HMAC
Failure cascade and construction.
Building MACs from Hash Functions
- CBC-MAC and CMAC are built from block ciphers (PRFs)
- What about building MACs from cryptographic hash functions instead?
- Cryptographic hash functions like SHA-256 are keyless: \(H : \mathcal{M} \to \mathcal{T}\)
- No secret key involved, so \(H(m)\) alone is not a MAC
- Anyone could compute \(H(m)\)!
- We need to incorporate a secret key somehow
- The obvious approaches all fail (in instructive ways!)
- Let’s walk through the failure cascade
Attempt 1: \(H(k \| m)\)
- Prepend the key to the message and hash
- This fails due to the length extension property of Merkle-Damgård hashes (a chained compression-function design used by SHA-256, which we’ll formalise shortly)
- SHA-256 processes input in blocks through a compression function
- The final internal state is the hash output
- Given \(H(k \| m)\), an attacker can continue hashing from that state
- They can compute \(H(k \| m \| \text{padding} \| m')\) without knowing \(k\)!
- This is exactly the cascade extension attack from CBC-MAC, in a different setting
- The hash function’s internal chaining is exploitable
Attempt 2: \(H(m \| k)\)
- Append the key to the message instead
- This blocks the length extension attack: the key comes last, so an adversary can’t extend
- But it’s vulnerable to collision attacks on \(H\)
- If the adversary finds \(m_0 \neq m_1\) with \(H(m_0) = H(m_1)\) (two distinct inputs with the same hash, called a collision)…
- …then \(H(m_0 \| k) = H(m_1 \| k)\) for any key \(k\)
- The adversary can forge without knowing the key!
- Collision resistance of the hash function directly limits MAC security
- For broken hashes (MD5, SHA-1), this is a real problem
Attempt 3: \(H(k \| m \| k)\)
- Sandwich the message between two copies of the key
- This blocks both extension attacks and simple collision attacks
- But the security analysis is fragile and depends on hash internals
- No clean reduction to standard hash function properties
- Difficult to prove secure in any standard model
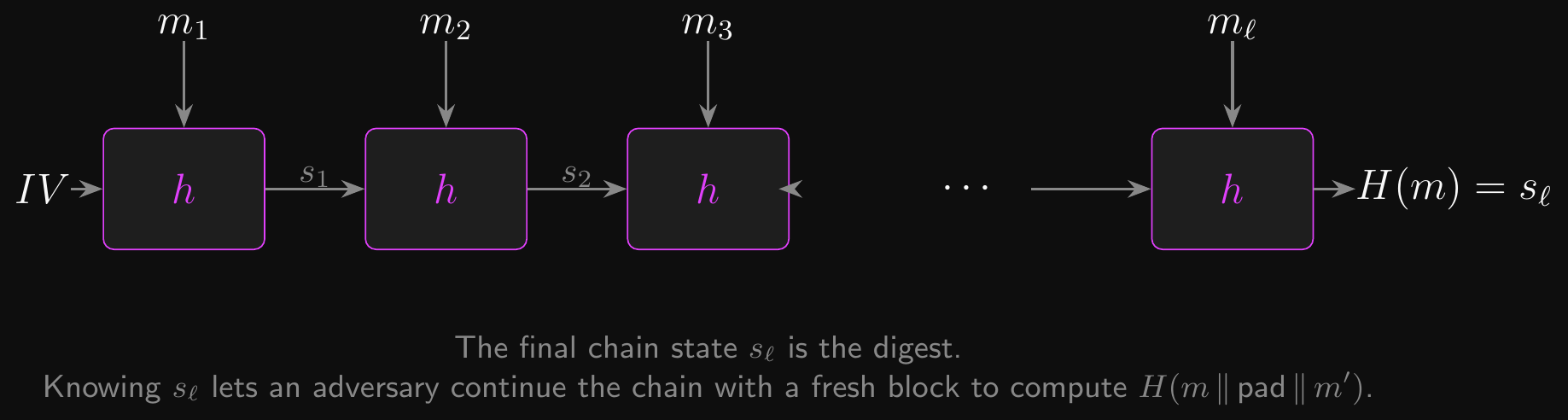
Merkle-Damgård: The Chain That Causes the Trouble
- Why did Attempts 1 and 2 fail? Both exploit how SHA-256 processes its input
- Merkle-Damgård construction: the design pattern behind MD5, SHA-1, SHA-2 and many others
- A fixed-input compression function \(h : \{0,1\}^n \times \{0,1\}^b \to \{0,1\}^n\)
- Process the message in \(b\)-bit blocks, chaining state through \(h\)
- Start with a fixed \(s_0 \leftarrow IV\), then \(s_i \leftarrow h(s_{i-1}, m_i)\)
- The final \(s_\ell\) is the digest
- Length extension property: the final state is also a valid input state for another block
- Given \(H(m) = s_\ell\), an adversary can compute \(H(m \| \text{pad} \| m')\) without knowing \(m\)
- They just keep chaining from \(s_\ell\) as if \(m\) had more blocks
- This is the same extension issue we saw with CBC-MAC, in a different setting
- SHA-3 uses the sponge construction instead and has no length extension
- But most deployed hashes (SHA-256, SHA-512) are still Merkle-Damgård
- HMAC was designed to work safely with MD hashes, so this still matters
Merkle-Damgård Construction
HMAC: The Solution
- HMAC uses a nested construction with two derived keys
- Let \(B\) be the block size of the hash function in bytes
- If key \(k\) is longer than \(B\) bytes, hash it: \(k' \leftarrow H(k)\)
- Otherwise, pad \(k\) with zero bytes until it’s \(B\) bytes long
- Derive two keys:
- Let
ipad= the byte0x36repeated \(B\) times,opad= the byte0x5Crepeated \(B\) times - \(k'_1 \leftarrow k' \oplus \text{ipad}\), \(k'_2 \leftarrow k' \oplus \text{opad}\)
- Let
The HMAC Construction
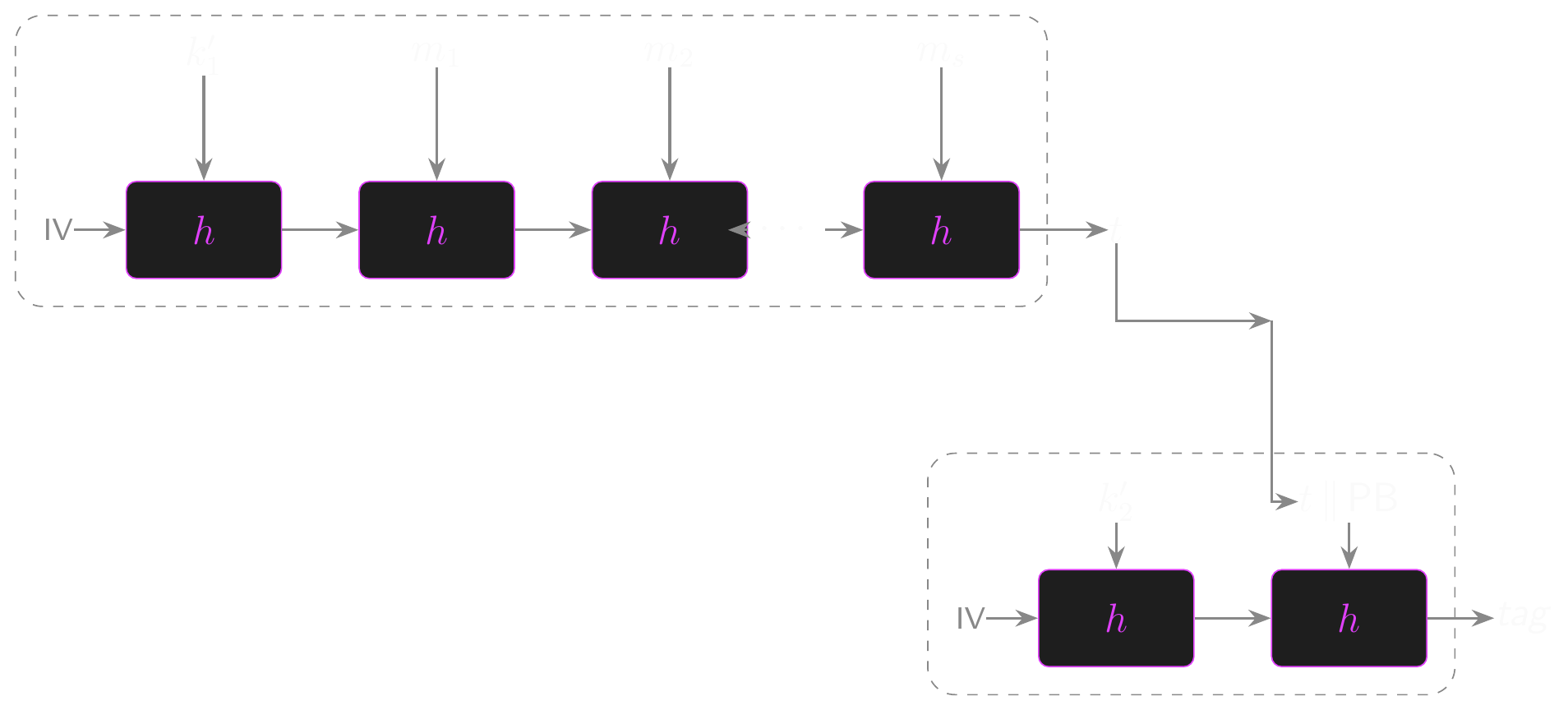
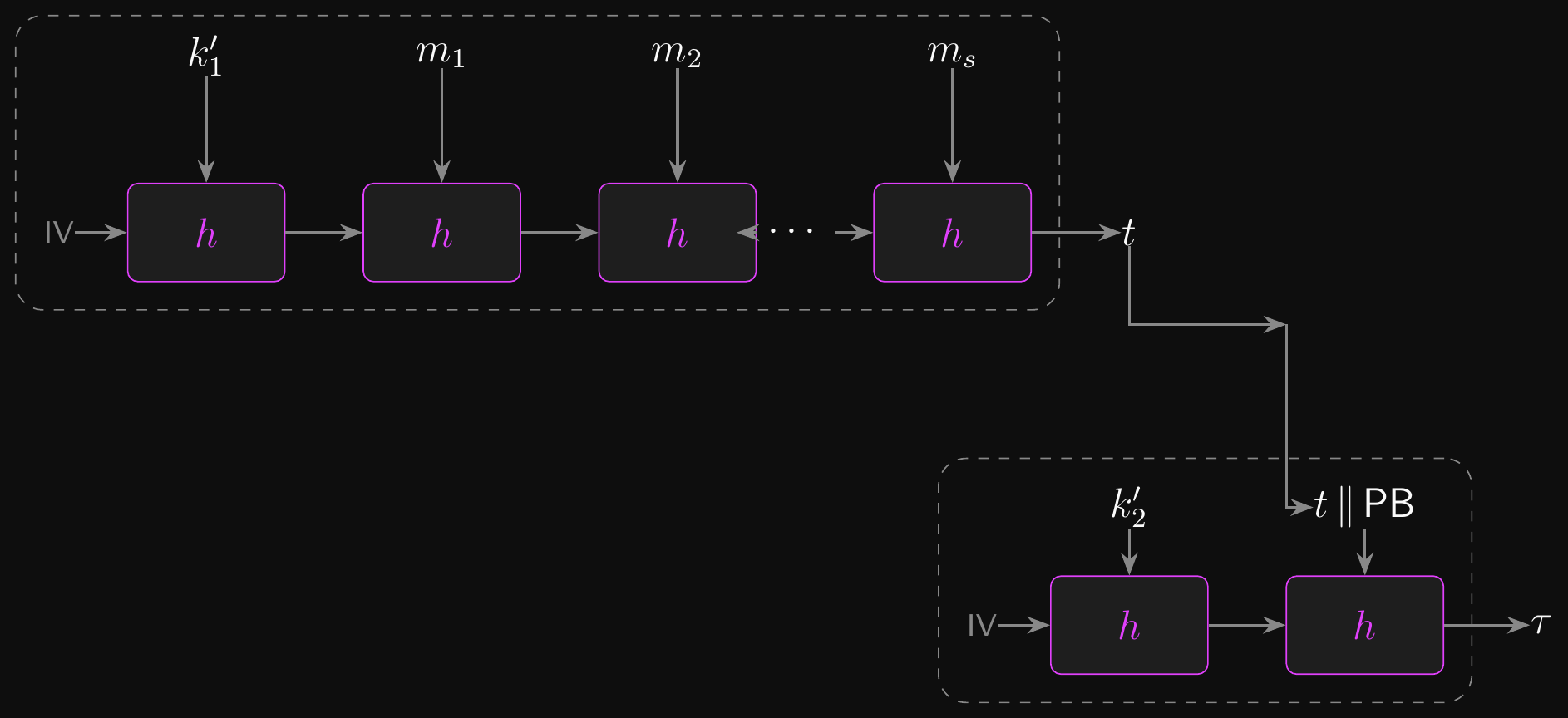
- \(\mathrm{HMAC}(k, m) = H(k'_2 \| H(k'_1 \| m))\)
- Inner hash: \(H(k'_1 \| m)\) compresses the keyed message to a fixed-size digest
- Outer hash: \(H(k'_2 \| \text{inner})\) applies a second keyed hash to the result
- Why does this work?
- Length extension on the inner hash gives \(H(k'_1 \| m \| \text{ext})\), but that value gets hashed again with a different key in the outer hash
- Collision attacks on the inner hash don’t help because the outer hash re-keys
HMAC Structure
HMAC in Practice
- HMAC is provably secure when the compression function of \(H\) is a PRF
- The chosen hash is appended to the name of the MAC
- E.g. HMAC-MD5, HMAC-SHA1 and HMAC-SHA256/384 are all found in TLS 1.2
- Dropped from TLS 1.3 in favour of AEAD
- HMAC’s security depends on that of the hash function selected
- Don’t throw a generic hash function into HMAC and expect good results!
- HMAC works with almost any strong cryptographic hash function
- And even some broken ones!
- HMAC-MD5 has no practical attacks (but shouldn’t be used)
- Tends to be much faster than CBC-MAC and other alternatives
Hash Function Properties
Collision resistance, preimage resistance, and the Random Oracle Model.
Cryptographic Hash Functions
- HMAC worked. Now let’s formalise the hash function properties we have been leaning on.
- What makes a hash function a cryptographic hash function (CHF)?
- SHA-256 is an example of a CHF
- MD5 is an example of an extremely broken CHF
- Collision resistance: it should be hard to find any two distinct messages \(m_0 \neq m_1\) such that \(H(m_0) = H(m_1)\)
- Can’t find two messages that produce the same digest!
- The birthday attack finds collisions in about \(2^{n/2}\) evaluations for an \(n\)-bit hash
- This is why SHA-256 (256-bit output) provides only 128-bit collision resistance
- Preimage resistance: given a digest \(t \in \mathcal{T}\), it should be hard to find any \(m \in \mathcal{M}\) such that \(H(m) = t\)
- The hash function should be irreversible
- Second preimage resistance: given some \(m_0\), it should be hard to find \(m_1 \neq m_0\) such that \(H(m_0) = H(m_1)\)
- Can’t change the message without changing the hash
- Avalanche effect: even a small change to the input should drastically change the output
These Properties are Not Equivalent
- For compressing hash functions, the implications form a chain:
- Collision resistance \(\Rightarrow\) 2nd-preimage resistance \(\Rightarrow\) preimage resistance
- Finding \(m_1\) given \(m_0\) with \(H(m_0) = H(m_1)\) is already a collision (CR \(\Rightarrow\) SPR)
- Inverting a hash gives a second preimage for most inputs (SPR \(\Rightarrow\) OW)
- The converses do NOT hold:
- Preimage resistance does NOT imply collision resistance
- A hash can be hard to invert but easy to find collisions for
- Precision matters when evaluating hash function security
- MD5 and SHA-1 have broken collision resistance
- Their preimage resistance is still considered intact (no practical attacks)
- But you still shouldn’t use them for new systems!
- SHA-256 and SHA-3 have no known breaks for any of these properties
- SHA-256 is Merkle-Damgård based (vulnerable to length extension, but not broken)
- SHA-3 uses the sponge construction (no length extension vulnerability)
The Random Oracle Model
- Sometimes we need a stronger assumption than collision resistance
- The Random Oracle Model (ROM) treats the hash function as a truly random function
- For every input, the output is uniformly random and independent
- The only way to learn \(H(m)\) is to query the oracle
- This is a heuristic, not a theorem: real hash functions are deterministic algorithms
- But the ROM gives us a framework for proving security of constructions like HMAC
- Why this matters for the next few lectures
- If \(H\) were truly random, an adversary cannot predict \(H(m)\) for any \(m\) they have not queried
- RSA-FDH signatures (L06) sign \(H(m)\) instead of \(m\): the signer cannot be tricked into signing a cleverly structured message, because \(H(m)\) looks random
- The ROM assumption is what makes that intuition into a proof
- You’ll see “secure in the ROM” throughout the public-key material
- It’s worth understanding what this means and what its limitations are
Authenticated Encryption
Combining secrecy and integrity.
The Composition Problem
- We now have two independent tools:
- CPA-secure encryption (confidentiality, from Lectures 02 & 03)
- Secure MACs (integrity, from this lecture)
- Real-world adversaries are active: they can tamper with ciphertexts in transit
- WiFi, Ethernet and Bluetooth can all be interfered with relatively easily
- CPA-secure schemes allow undetected tampering with ciphertext
- But breaking integrity can also break secrecy!
- We should always combine encryption with authentication
- But the order of composition matters!
Three Compositions
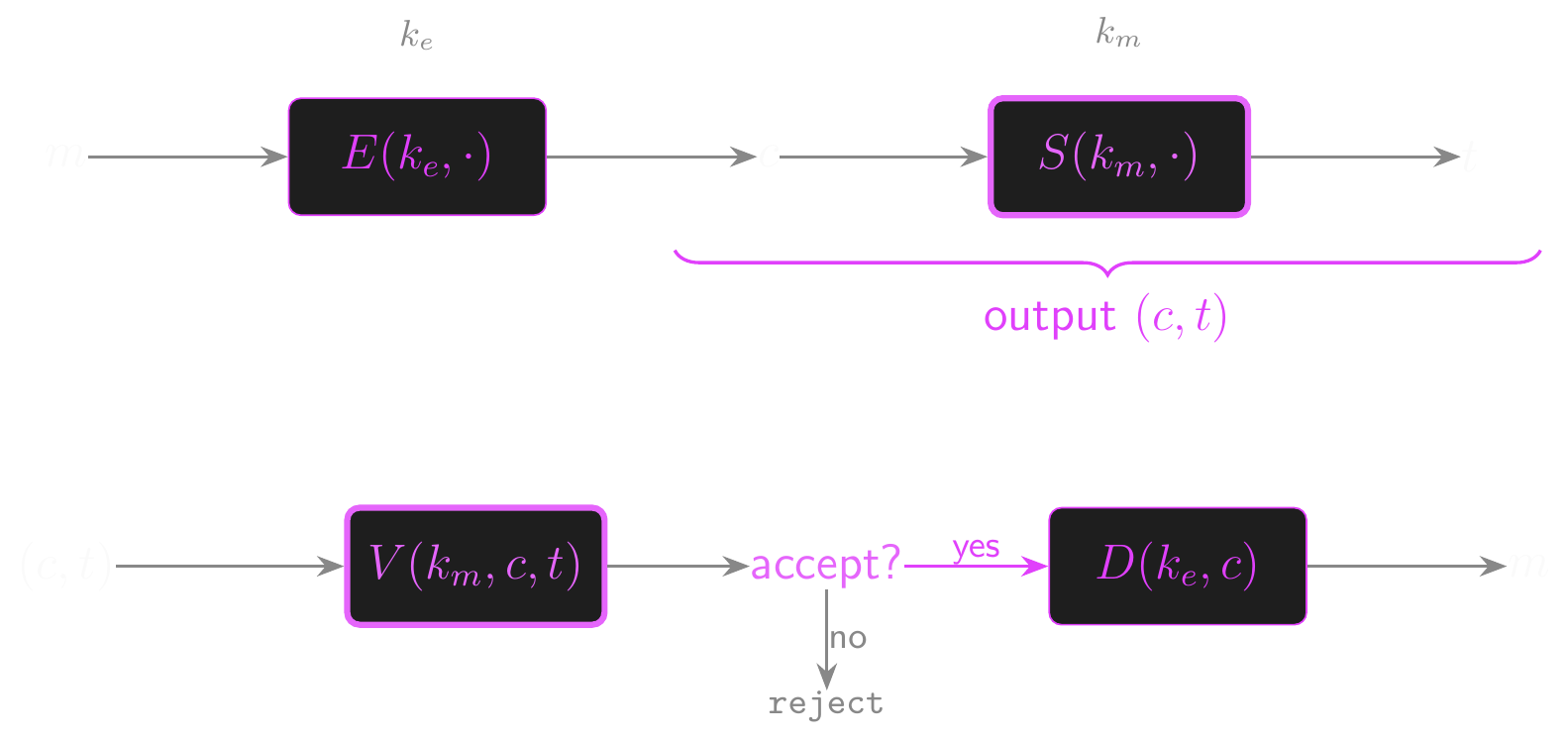
- Encrypt-then-MAC: encrypt \(m\), then MAC the ciphertext
- \(c \leftarrow E(k_{\text{encrypt}}, m)\), \(t \leftarrow S(k_{\text{mac}}, c)\), output \((c, t)\)
- To decrypt: check MAC first, reject if invalid, then decrypt
- Secure in general! If the MAC is secure, the adversary can’t submit valid modified ciphertexts
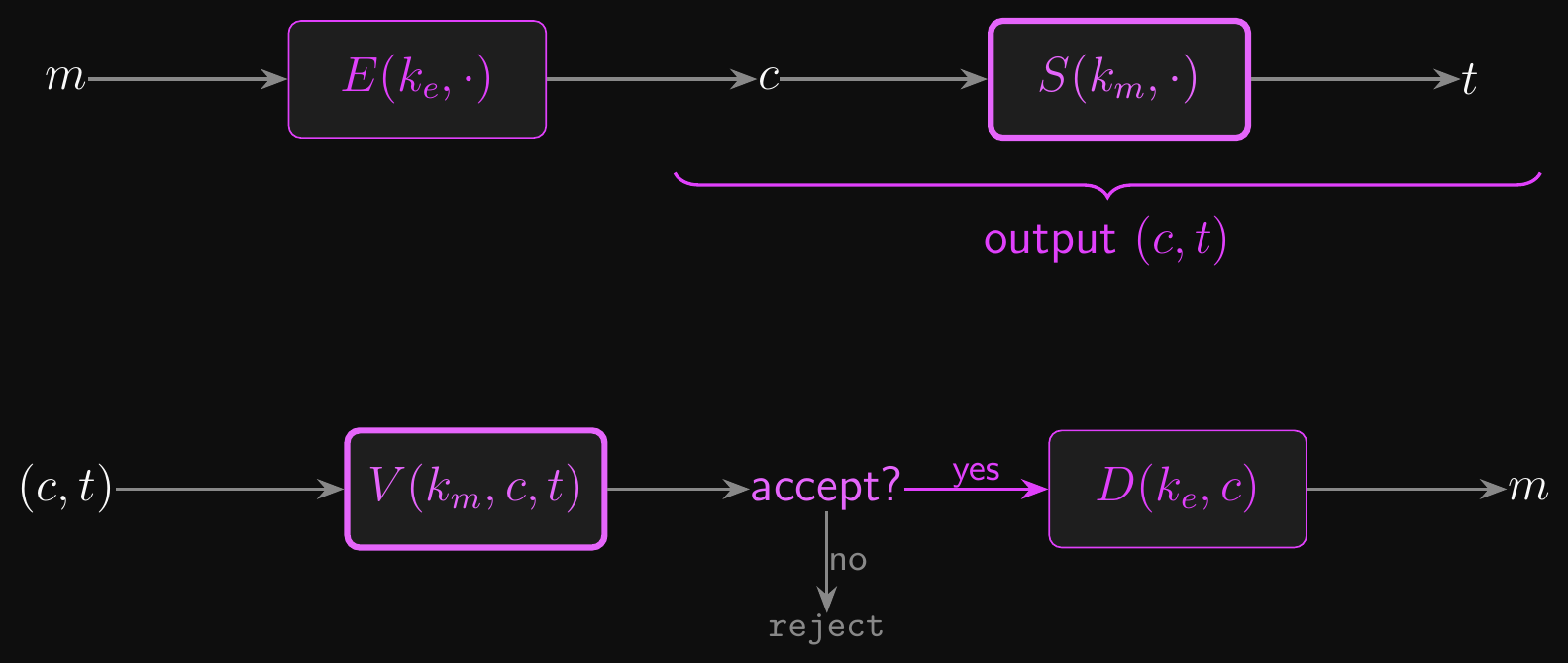
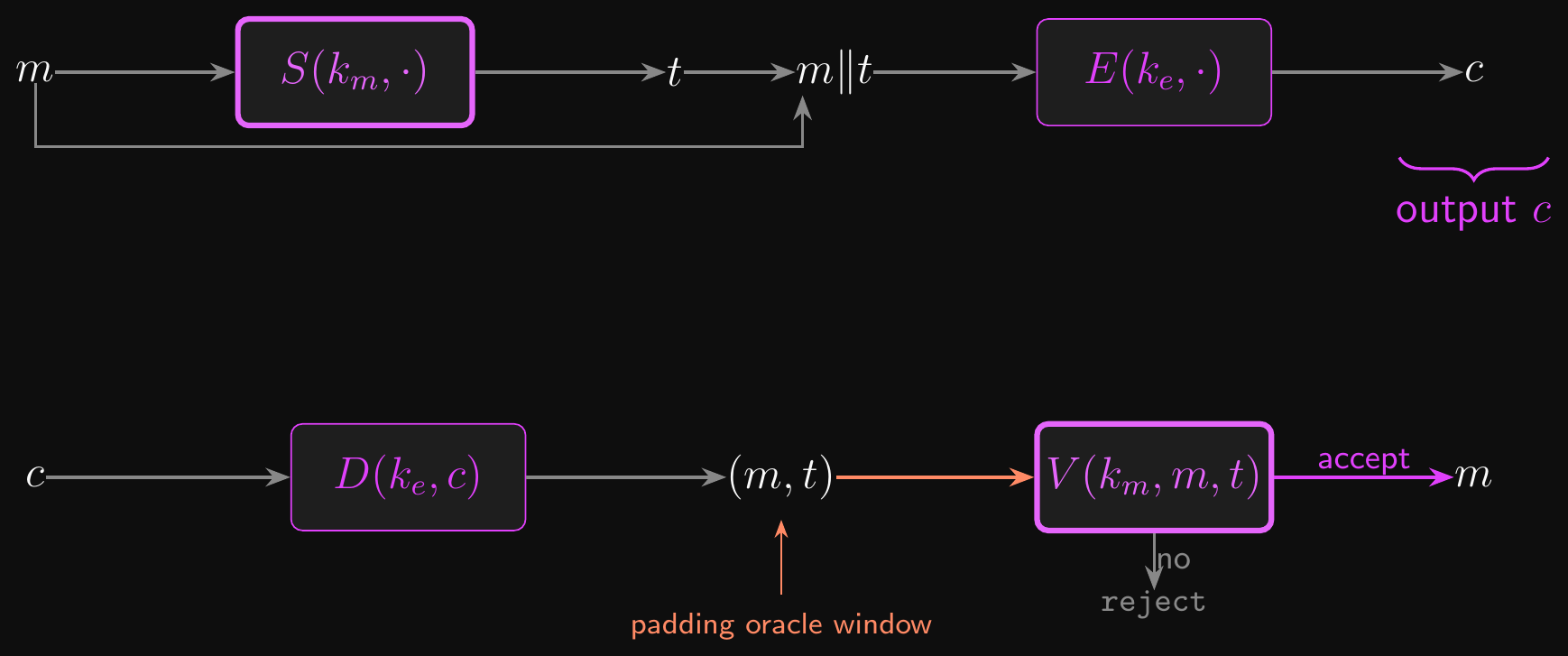
- MAC-then-Encrypt: MAC the message, then encrypt message and tag together
- \(t \leftarrow S(k_{\text{mac}}, m)\), \(c \leftarrow E(k_{\text{encrypt}}, (m, t))\), output \(c\)
- Not generally secure! Padding attacks are devastating
- The POODLE attack against SSL 3.0 exploits exactly this weakness
- All TLS 1.0-1.2 CBC cipher suites used MAC-then-Encrypt; TLS 1.3 dropped them entirely
- Encrypt-and-MAC: encrypt \(m\) and MAC \(m\) independently
- \(c \leftarrow E(k_{\text{encrypt}}, m)\), \(t \leftarrow S(k_{\text{mac}}, m)\), output \((c, t)\)
- Not generally secure! The MAC tag may leak information about \(m\)
- Both keys must be independent in all cases: \(k_{\text{encrypt}} \neq k_{\text{mac}}\)
Encrypt-then-MAC
MAC-then-Encrypt
The CCA Theorem
- Encrypt-then-MAC with a CPA-secure cipher and a secure MAC achieves IND-CCA2 security
- CCA2 is the strongest standard notion of encryption security
- We’ll define IND-CCA2 formally in Lecture 06 and prove this theorem in Lecture 07
- The intuition: the MAC prevents the adversary from submitting modified ciphertexts
- Any modification invalidates the tag
- So the CCA2 decryption oracle is effectively neutered
- The adversary is left with only chosen-plaintext capability, which CPA handles
- This is why modern protocols exclusively use authenticated encryption
- There is no good reason to use encryption without authentication
Authenticated Encryption (AE)
- An authenticated encryption scheme combines confidentiality and integrity into a single primitive
- A single algorithm pair \((E, D)\) that provides both CPA-style secrecy and MAC-style unforgeability
- AE security is the property of achieving both simultaneously
- A cipher is AE-secure if:
- It is CPA-secure: no information about the plaintext leaks from the ciphertext
- And ciphertext integrity (CI) holds: the adversary cannot produce a new ciphertext that decrypts to anything other than
reject
- The CCA theorem says Encrypt-then-MAC gives us exactly this: AE from CPA + MAC
- We’ll use “AE-secure” as shorthand for this combined guarantee from here on
- In L06 we’ll prove AE implies IND-CCA2
One-Time Security
- Sometimes we can make do with a weaker property instead of AE security
- In some contexts, like encrypted emails, we might use ephemeral keys
- And each ephemeral key might be used for only a single message
- In that case, being AE-secure is more than sufficient
- We could weaken the definition to one-time AE security
- The adversary will only get a single attempt at each key in practice
- So why not make the definition of security reflect that?
- Typically, we use the same CPA-secure symmetric cipher as usual
- Remember the polynomial one-time MAC? Combined with a CPA-secure cipher, it gives one-time AE
- Unforgeable if the adversary only gets a single chosen-message query
CCA Security
- The good news is that an AE-secure symmetric cipher is also CCA-secure
- So long as we’re doing authenticated encryption, we’re secure against chosen-ciphertext attacks
- There’s little-to-no reason to use any symmetric cipher that isn’t AE-secure
- TLS 1.3 includes some gold-standard AE constructs
- AES-GCM
- AES-CCM
- ChaCha20-Poly1305
- These are AEAD schemes: authenticated encryption with associated data
Universal Hashing
Fast, one-time, composable.
Universal Hash Functions
- A universal hash function (UHF) is a keyed hash \(h : \mathcal{K} \times \mathcal{M} \to \mathcal{T}\) where collisions are rare across the key
- For any two distinct messages \(m_0 \neq m_1\): \(\Pr_k[h(k, m_0) = h(k, m_1)] \leq \varepsilon\)
- \(\varepsilon\) is a small collision bound, typically \(v/|\mathcal{T}|\) where \(v\) is the number of message blocks
- We have already seen a UHF: the polynomial \(P_m(k_1) = a_1 k_1^v + \cdots + a_v k_1\) from the one-time MAC
- Two distinct messages give polynomials that agree on at most \(v\) out of \(p\) values of \(k_1\)
- That is exactly the UHF collision bound
- The \(k_2\) mask in the one-time MAC was a separate ingredient. The polynomial alone is just a UHF.
- Two UHFs we will meet in the next few slides:
- Poly1305: polynomial hash in \(\text{GF}(2^{130}-5)\), used in ChaCha20-Poly1305
- GHASH: polynomial hash in \(\text{GF}(2^{128})\), used in AES-GCM
- UHFs are fast, parallelisable and easy to analyse
- But a UHF is not a MAC: an adversary who sees two outputs can solve for the key
- To build a multi-message MAC we need one more ingredient: a PRF to mask each output
Carter-Wegman: From UHF to Full MAC
- A UHF is one-time only. A PRF is multi-message but slow on long input. Combine them.
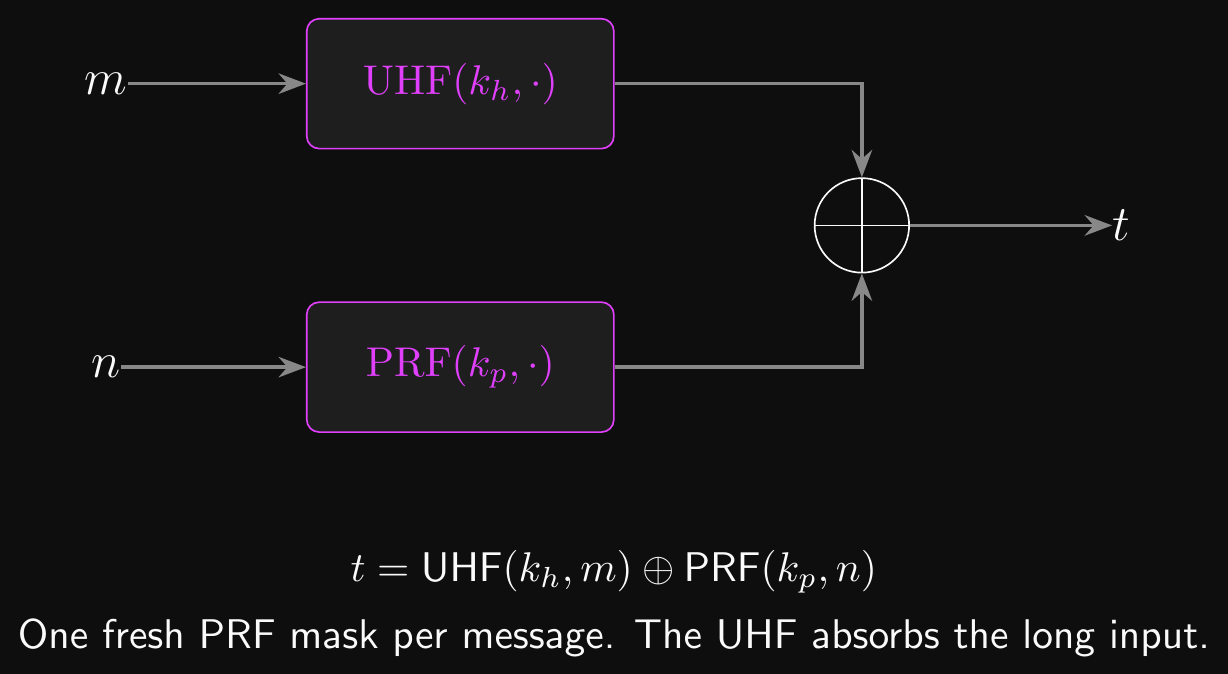
- Carter-Wegman MAC: \(\text{tag} = \text{UHF}(k_h, m) \oplus \text{PRF}(k_p, \text{nonce})\)
- \(k_h\) is the UHF key, reused across messages
- \(k_p\) is the PRF key, also reused
- The nonce is fresh for every message
- The PRF output acts as a one-time pad on the UHF output
- Each \((k_p, \text{nonce})\) pair produces an independent mask
- So the UHF output is masked by fresh randomness, the way \(k_2\) masked the polynomial MAC earlier
Carter-Wegman in the Wild
- This is literally how ChaCha20-Poly1305 works
- UHF is Poly1305. The PRF mask is the first block of a ChaCha20 keystream at the nonce.
- AES-GCM uses the same pattern with one AES key for both roles
- The UHF key is \(H = E(k, 0^{128})\), derived from the single AES key
- The PRF mask is \(E(k, J_0)\), where \(J_0\) is a counter block derived from the nonce
- Why it’s fast: one PRF call per message. The UHF handles the bulk of the input.
Carter-Wegman Structure
AEAD in Practice
Associated data and nonce discipline.
AEAD: Authenticated Encryption with Associated Data
- Real-world protocols often need to authenticate metadata alongside the message
- Packet headers must be readable for routing but protected from tampering
- Metadata in secure file systems should be visible but not malleable
- A nonce-based AEAD cipher \(\mathcal{E} = (E, D)\) takes four inputs:
- Key \(k \in \mathcal{K}\), message \(m \in \mathcal{M}\), associated data \(d \in \mathcal{D}\), nonce \(n \in \mathcal{N}\)
- Encryption: \(c = E(k, m, d, n)\)
- Decryption: \(m = D(k, c, d, n)\), or
rejectif integrity check fails - The authentication tag covers both the ciphertext and the associated data
- Tampering with either one is detected on decryption
- If \(d\) is empty, behaves like ordinary authenticated encryption
- If \(m\) is empty, behaves like a MAC over the associated data
Nonce vs IV vs Salt
- All three are non-secret auxiliary inputs. The rules they obey are different.
- Nonce (AEAD): must be unique per key
- Can be a counter, does not need to be random or secret
- Nonce reuse is the operational cliff edge for AEAD
- IV (CBC mode, L03): must be unpredictable per ciphertext
- Typically fresh random bytes. Predictable IVs break CPA security.
- Salt (password hashing, L07): must be unique per user
- Does not need to be secret, random or unpredictable. Just unique.
- Confusing these three is one of the most common production crypto bugs
- “I reused the IV but it was random” is not the same property as “unique nonce”
AES-GCM
- Galois Counter Mode (GCM) is the most widely deployed AEAD cipher
- Standardized by NIST in 2007; used in TLS 1.3, IPsec, and many other protocols
- We’ll step through it in detail in another lecture
- GCM follows encrypt-then-MAC internally: AES-CTR for secrecy, GHASH for integrity
- Hardware support makes AES-GCM extremely fast on modern processors
- AES-NI accelerates the CTR side,
PCLMULQDQaccelerates the GHASH field multiplications
- AES-NI accelerates the CTR side,
ChaCha20-Poly1305
- The alternative when AES hardware support is unavailable
- ChaCha20 is a stream cipher (from Lecture 02)
- Poly1305 is a polynomial one-time MAC (recall the construction from earlier)
- Combined as an AEAD cipher in RFC 7539
- Both AES-GCM and ChaCha20-Poly1305 are available in TLS 1.3
- Either is a good choice for the EPIC project’s secure messaging component
What Not to Do
- AEAD schemes require a unique nonce for every encryption under the same key
- The nonce doesn’t have to be secret, just unique
- Can be transmitted in the clear alongside the ciphertext
- TLS 1.3 derives a per-connection IV and XORs it with the record sequence number, guaranteeing uniqueness without randomness
- Nonce reuse in AES-GCM is catastrophic
- Two messages encrypted with the same key and nonce: plaintexts are leaked via XOR
- The authentication key \(H\) is exposed, breaking ciphertext integrity entirely
- Not just the two affected messages: all messages under that key are compromised
Misuse Resistance and Block Limits
- AES-GCM-SIV provides some nonce misuse resistance at the cost of performance
- Still leaks whether two plaintexts are equal under nonce reuse
- But doesn’t catastrophically break authentication
- There are subtle limits on the amount of data that can be securely encrypted using GCM under a single key
- The nonce is usually (but not always) 96 bits
- We’ll cover these in detail when we prep for the EPIC, but you should be aware of them now!
Conclusion
What did we learn?
Where do we go from here?
- We’ve solved the integrity problem that CTR mode and CPA-secure ciphers left open
- Message authentication via MAC systems (UF-CMA security)
- Building MACs from PRFs (with a full security reduction)
- Building MACs from hash functions (HMAC and the failure cascade)
- Combining encryption and authentication (authenticated encryption)
- But every symmetric primitive assumes a pre-shared key
- How did Alice and Bob get the key in the first place?
- Kerckhoffs’s principle means the key is the only secret
- Key establishment is the existential problem of symmetric cryptography
- Next lecture: public key cryptography and key exchange
For next time…
- Reading: Chapters 6, 7 and 8 of A Graduate Course in Applied Cryptography
- I’m not suggesting that you actually read all of it!
- Skim through it and use it to get a deeper understanding of anything that didn’t click in the lecture
- Text too dense? Feed it into an LLM and start asking questions!
- Crypto 101 covers the same material less formally if you prefer that style
- We’ll essentially prep a chunk of the EPIC each week for the rest of the course!
- Of course, the final exam can only test up to and including Week 6…
Questions?
Ask now, catch me after class, or email eoin@eoin.ai